Reanalysis of Chen & Wyble, 2015
Chen and Wyble published an interesting paper (2015) where they demonstrate that participants cannot report attributes of attended stimuli unless the participants are previously informed that this attribute is important. For instance, you wouldn’t remember the color of the apple if you had had just told someone the shape. I would have expected the opposite, so … cool!
After reading the paper (you can check it out at http://wyblelab.com/publications), I became curious whether participants might unconsciously retain some information about these forgotten attributes. Chen and Wyble posted their data to databrary.com (https://nyu.databrary.org/volume/79), so I downloaded the data and did some quick analyses that you see here! I want to commend Chen and Wyble for sharing their data. This is something everyone should start doing (including me).
Below, I will start by showing I can replicate Chen and Wyble’s analyses, then I will investigate whether there’s a trace of unconscious memory for the “forgotten” features.
EDIT -12/22/15- Brad Wyble recently pointed out that I overstated the claim in their paper. They do not claim participants have complete amnesia for unqueried object attributes. Rather, Chen and Wyble focus on the dramatic performance change between the first and second trial following the initial query about an object attribute. This performance change demonstrates amnesia, but not necessarily complete amnesia.
References
Chen, H., & Wyble, B. (2015). Amnesia for Object Attributes Failure to Report Attended Information That Had Just Reached Conscious Awareness. Psychological science, 26(2),203-210.
Wyble, B. (2014). Amnesia for object attributes: Failure to report attended information that had just reached conscious awareness. Databrary. Retrieved November 22, 2015 from http://doi.org/10.17910/B7G010
Load relevant libraries and write analysis functions
I’ll start by loading the python libraries that I’ll use throughout analyses.
1 2 3 4 5 6 7 8 9 | |
Here are some quick functions I wrote for running different statistical tests and plotting the data. I won’t explain this code, but encourage you to look through it later if you’re wondering how I did any of the analyses.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 | |
Experiment 1
Next, load Experiment 1 data
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
The data is loaded, lets just take a quick look at the data after loading it in.
1
| |
| Sub# | Block | Trial# | TarCol | Tar_Iden | Tar_Loc | Col_Resp | Iden_Resp | Loc_Resp | Col_Acc | Iden_Acc | Loc_Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 1 | 2 | 1 | 2 | 4 | 0 | 0 | 2 | 0 | 0 | 0 |
| 1 | 6 | 1 | 3 | 3 | 4 | 3 | 0 | 0 | 3 | 0 | 0 | 1 |
| 2 | 6 | 1 | 4 | 1 | 3 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 3 | 6 | 1 | 5 | 3 | 1 | 4 | 0 | 0 | 4 | 0 | 0 | 1 |
| 4 | 6 | 1 | 6 | 2 | 2 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
I want to create a new variable.
Before explaining the new variable, I should explain a little about Chen and Wyble’s experiment. Half the participants were instructed to find the letter among numbers and the other half were instructed to find the number among letters. 4 items were briefly flashed on the screen (150 ms) then participants reported where the target item had been. Each of the 4 items was a different color.
Participants reported target location for 155 trials. On the 156th trial, the participants reported the target location then (to their surprise) reported what specific letter/number the target was and what color it was. Even though participants knew where the target was, they had no idea what either the target’s letter/number or color were. They had “forgotten” what the target was (even though they must have known what the target was when they initially located it).
The new variable will code whether the trial is a “pre-surprise” trial (trials 1-155), a surprise trial (trial 156) or the trial after the surprise (trial 157).
I’ll call this variable “TrialType”
TrialType: 0=Presurprise; 1=Surprise Trial; 2=Postsurprise trials.
1 2 | |
Experiment 1: Replicating Chen & Wyble’s (2015) analyses
Lets just take a quick look at overall accuracy. Make sure everyone is doing ok on the task. Below I plot the mean accuracy of each participant…looks like participant 23 struggled a little. Chen and Wyble (2015) notes that no participants were excluded or replaced.
I might have replaced participant 23 since his/her accuracy is easily 2.5 standard deviations below the mean accuracy (I print this value below)…seems like participant 23 was doing something different in this task.
1 2 3 4 5 6 7 8 9 10 11 | |
mean accuracy
0.89
standard deviation of accuracies
0.07
2.5 standard deviations below mean accuracy
0.71

Lets look at participants’ performance when asked to identify the target’s location. I will plot performance as mean accuracy in the presurprise,surprise, and postsurprose trials.
I will also run some quick statistical tests. For these tests, I take the arcsine of the square root of the accuracies (Rao, 1960) to increase the accuracies’ normality (I use adj. to indiciate that the tested data is transformed). I test whether this worked with a Shapiro-Wilk test of normality. If the p-value of the Shapiro-Wilk test is greater than 0.1, I run a t test to see if the accuracy in the two conditions is significantly different. If the p-value of the Shapiro-Wilk test is less than or equal to 0.1, then I run a Wilcoxon signed rank test since this test does not care about normality.
1 2 3 | |
---------------------------------
Mean Presurprise: 0.89
Mean Surprise: 0.8
Mean Postsurprise: 0.79
Presurprise - Surprise: 0.09
Postsurprise - Surprise: -0.01
Postsurprise - Presurprise: 0.09
---------------------------------
Presurprise vs Surprise
normality test adj. Test value: 0.64 P-value: 0.0
Wilcoxon. Test value: 74.0 P-value: 0.25
Postsuprise vs Surprise
normality test adj. Test value: 0.8 P-value: 0.001
Wilcoxon. Test value: 33.0 P-value: 0.63
Presurprise vs Postsurprise
normality test adj. Test value: 0.94 P-value: 0.2857
T-test adj. Test value: 0.92 P-value: 0.3695
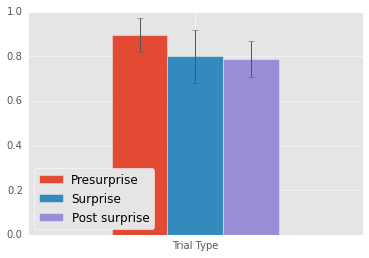
The y-axis represents percent correct. All graphs in this post will have percent correct on the y-axis.
Replicating Chen and Wyble, participants perform no worse in the surprise and post surprise trials, indicating that they succesfully found the target.
Now lets look at participants’ ability to report the target’s color in the surprise trial and the trial immediately following the surprise test.
Below I plot the percent of participants that correctly identified the target’s color in the surprise and post-surprise trials
1 2 3 4 | |
---------------------------------
Mean Surprise: 0.3
Mean Postsurprise: 0.7
Postsurprise - Surprise: 0.4
---------------------------------
Postsurprise vs Surprise
Surprise Test. Comparison to Chance: 17.0 P-value: 0.5899
After Surprise Test. Comparison to Chance: 33.0 P-value: 0.024
Chi-Square Comparison: 6.4 P-value: 0.0114
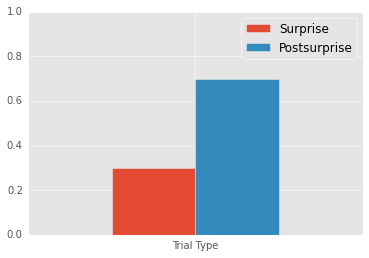
We perfectly replicate Chen and Wyble; participants respond more accurarely in the post-surprise trial than in the surprise trial.
The next cell examines participants’ ability to report the target’s identity on the surprise trial and the trial immediately following the surprise trial. Remember, the participants locate the target based on whether its a letter or number, so they know the broad category of the target. Nonetheless, they cannot report the target’s identity on the surprise trial
1 2 3 4 | |
---------------------------------
Mean Surprise: 0.25
Mean Postsurprise: 0.75
Postsurprise - Surprise: 0.5
---------------------------------
Postsurprise vs Surprise
Surprise Test. Comparison to Chance: 15.0 P-value: 0.7226
After Surprise Test. Comparison to Chance: 35.0 P-value: 0.014
Chi-Square Comparison: 10.0 P-value: 0.0016
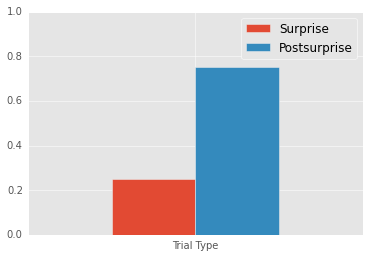
Experiment 1 - Intertrial analyses
So far, I’ve perfectly replicated Chen & Wyble (which is good since this is their data).
Now I want to see if the target’s color or identity on the previous trial influences the current trial’s performance in the location task. I am only examining presurprise trials, so this should be trials when the participants don’t “remember” the target’s color or identity.
First I want to make some variables representing whether the target’s color and identity repeat across trials.
1 2 3 4 5 | |
Lets see what happens when the target’s color and identity repeat.
1 2 3 4 5 | |
---------------------------------
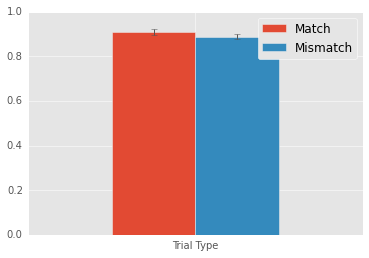
Mean match: 0.918
Mean mismatch: 0.8925
Match - Mismatch: 0.0255
---------------------------------
Match vs Mismatch
normality test adj. Test value: 0.92 P-value: 0.0821
Wilcoxon. Test value: 51.0 P-value: 0.04

Looks like a 2.5% increase in accuracy. Now, this wasn’t really a planned comparison, so please take this result with a grain of salt.
As a sanity check, lets look at how repetitions in the target’s location (the reported feature) effect performance.
We have to quickly create a new variable coding target location repetitions
1 2 | |
1 2 3 4 | |
---------------------------------
Mean match: 0.9101
Mean mismatch: 0.8883
Match - Mismatch: 0.0218
---------------------------------
Match vs Mismatch
normality test adj. Test value: 0.93 P-value: 0.1812
T-test adj. Test value: 2.62 P-value: 0.0168
Target location repetitions lead to a 2% increase in performance. Again, this result is robust.
It’s a good sign that this effect is about the same size as repetitions in the unreported features.
Replicate Experiments 1 Intertrial Analyses with Experiment 1b
Experiment 1 had some evidence that participants unconsciously knew the color and identity of the target, since they performed a little better when the color and identity repeated. The effect was small, so I am not 100% confident that it’s robust.
The best way to demonstrate that this effect is real would be to show that it also exists in another similar Experiment. Chen and Wyble provide a replication of Experiment 1. In this experiment, the only difference is the target and distractors appear for longer and are not masked (making them easier to see).
If participants response more accurately when the target color and identity repeat in Experiment 1b, then we can be a little more confident that participants are unconsciously aware of the target’s color and identity.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 2 | |
---------------------------------
Mean match: 0.9716
Mean mismatch: 0.9644
Match - Mismatch: 0.0072
---------------------------------
Match vs Mismatch
normality test adj. Test value: 0.93 P-value: 0.1875
T-test adj. Test value: 2.81 P-value: 0.0112
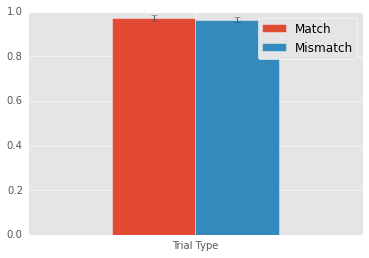
Wow. Only a 1% change in accuracy, so again not big. Nonetheless, this result is signficant. So, Some evidence that participants perform a little better when the targets’ color and identity repeat.
This suggests that participants retain some information about the targets’ color and identity even though they cannot explicitly report these attributes.
Now, I would probably want to replicate this result again before trusting it, but I’m relatively confident that participants unconsciously retain some information about the target’s color and identity.