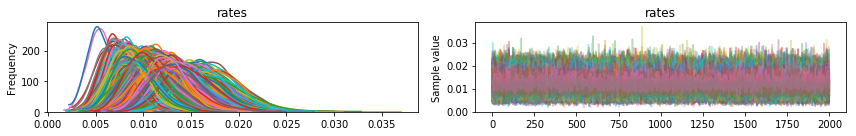I’m a checklist addict. While our team has a document on acquiring different accounts, reviewing our workflows, reviewing code repos etc., this document doesn’t provide any prioritization.
I created the following checklist (markdown) to give a condensed view of what a manager and new hire should accomplish by the end of the first week following a new hire’s start.
I wasn’t able to find existing onboarding checklists so I hope you find this useful!
I was recently asked to post a series of parquet collection as tables so analysts could query them in SQL. This should be straight forward, but it took me awhile to figure out. Hopefully, you find this post before spending too much time on such an easy task.
You should use the CREATE TABLE. This is pretty straight forward. By creating a permanent table (rather than a temp table), you can use a database name. Also, by using a table (rather than a view), you can load the data from an s3 location.
Next, you can specify the table’s schema. Again, this is pretty straight forward. Columns used to partition the data should be declared here.
Next, you can specify how the data is stored (below, I use Parquet) and how the data is partitioned (below, there are two partitioning columns).
Finally, you specify the data’s location.
The part that really threw me for a loop here is that I wasn’t done yet! You need one more command so that Spark can go examine the partitions - MSCK REPAIR TABLE. Also please note that this command needs to be re-run whenever a partition is added.
Imbalanced classes is a common problem. Scikit-learn provides an easy fix - “balancing” class weights. This makes models more likely to predict the less common classes (e.g., logistic regression).
The PySpark ML API doesn’t have this same functionality, so in this blog post, I describe how to balance class weights yourself.
Generate some random data and put the data in a Spark DataFrame. Note that the input variables are not predictive. The model will behave randomly. This is okay, since I am not interested in model accuracy.
PySpark needs to have a weight assigned to each instance (i.e., row) in the training set. I create a mapping to apply a weight to each training instance.
To create the CDF I need to use a window function to order the data. I can then use percent_rank to retrieve the percentile associated with each value.
The only trick here is I round the column of interest to make sure I don’t retrieve too much data onto the master node (not a concern here, but always good to think about).
After rounding, I group by the variable of interest, again, to limit the amount of data returned.
A CDF should report the percent of data less than or equal to the specified value. The data returned above is the percent of data less than the specified value. We need to fix this by shifting the data up.
When onehot-encoding columns in pyspark, column cardinality can become a problem. The size of the data often leads to an enourmous number of unique values. If a minority of the values are common and the majority of the values are rare, you might want to represent the rare values as a single group. Note that this might not be appropriate for your problem. Here’s some nice text describing the costs and benefits of this approach. In the following blog post I describe how to implement this solution.
I begin by importing the necessary libraries and creating a spark session.
Next create the custom transformer. This class inherits from the Transformer, HasInputCol, and HasOutputCol classes. I also call an additional parameter n which controls the maximum cardinality allowed in the tranformed column. Because I have the additional parameter, I need some methods for calling and setting this paramter (setN and getN). Finally, there’s _tranform which limits the cardinality of the desired column (set by inputCol parameter). This tranformation method simply takes the desired column and changes all values greater than n to n. It outputs a column named by the outputCol parameter.
classLimitCardinality(Transformer,HasInputCol,HasOutputCol):"""Limit Cardinality of a column."""@keyword_onlydef__init__(self,inputCol=None,outputCol=None,n=None):"""Initialize."""super(LimitCardinality,self).__init__()self.n=Param(self,"n","Cardinality upper limit.")self._setDefault(n=25)kwargs=self._input_kwargsself.setParams(**kwargs)@keyword_onlydefsetParams(self,inputCol=None,outputCol=None,n=None):"""Get params."""kwargs=self._input_kwargsreturnself._set(**kwargs)defsetN(self,value):"""Set cardinality limit."""returnself._set(n=value)defgetN(self):"""Get cardinality limit."""returnself.getOrDefault(self.n)def_transform(self,dataframe):"""Do transformation."""out_col=self.getOutputCol()in_col=dataframe[self.getInputCol()]return(dataframe.withColumn(out_col,(F.when(in_col>self.getN(),self.getN()).otherwise(in_col))))
Now that we have the tranformer, I will create some data and apply the transformer to it. I want categorical data, so I will randomly draw letters of the alphabet. The only trick is I’ve made some letters of the alphabet much more common than other ones.
Now to apply the new class LimitCardinality after StringIndexer which maps each category (starting with the most common category) to numbers. This means the most common letter will be 1. LimitCardinality then sets the max value of StringIndexer’s output to n. OneHotEncoderEstimator one-hot encodes LimitCardinality’s output. I wrap StringIndexer, LimitCardinality, and OneHotEncoderEstimator into a single pipeline so that I can fit/transform the dataset at one time.
Note that LimitCardinality needs additional code in order to be saved to disk.
A quick improvement to LimitCardinality would be to set a column’s cardinality so that X% of rows retain their category values and 100-X% receive the default value (rather than arbitrarily selecting a cardinality limit). I implement this below. Note that LimitCardinalityModel is identical to the original LimitCardinality. The new LimitCardinality has a _fit method rather than _transform and this method determines a column’s cardinality.
In the _fit method I find the proportion of columns that are required to describe the requested amount of data.
In a previous post, I described how to download and clean data for understanding how likely a baseball player is to hit into an error given that they hit the ball into play.
This analysis will statistically demonstrate that some players are more likely to hit into errors than others.
Errors are uncommon, so players hit into errors very infrequently. Estimating the likelihood of an infrequent event is hard and requires lots of data. To acquire as much data as possible, I wrote a bash script that will download data for all players between 1970 and 2018.
This data enables me to use data from multiple years for each player, giving me more data when estimating how likely a particular player is to hit into an error.
123456789101112
%%bash
for i in {1970..2018};doecho"YEAR: $i" ../scripts/get_data.sh ${i};donefind processed_data/* -type f -name 'errors_bip.out'|\ xargs awk '{print $0", "FILENAME}'|\ sed s1processed_data/11g1 |\ sed s1/errors_bip.out11g1 > \ processed_data/all_errors_bip.out
The data has 5 columns: playerid, playername, errors hit into, balls hit into play (BIP), and year. The file does not have a header.
I have almost 39,000 year, player combinations…. a good amount of data to play with.
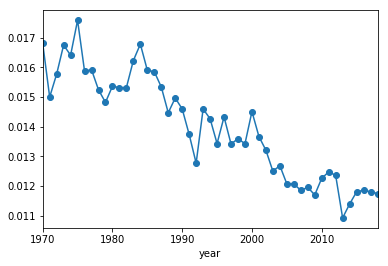
While exploring the data, I noticed that players hit into errors less frequently now than they used to. Let’s see how the probability that a player hits into an error has changed across the years.
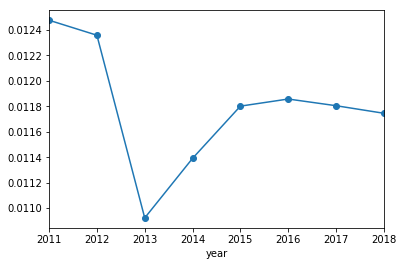
Interestingly, the proportion of errors per BIP has been dropping over time. I am not sure if this is a conscious effort by MLB score keepers, a change in how hitters hit, or improved fielding (but I suspect it’s the score keepers). It looks like this drop in errors per BIP leveled off around 2015. Zooming in.
Again, errors are very rare, so I want know how many “trials” (BIP) I need for a reasonable estimate of how likely each player is to hit into an error.
I’d like the majority of players to have at least 5 errors. I can estimate how many BIP that would require.
1
5./ERROR_RATE
423.65843413978496
Looks like I should require at least 425 BIP for each player. I round this to 500.
1
GROUPED_DF=GROUPED_DF[GROUPED_DF["bip"]>500]
1
GROUPED_DF=GROUPED_DF.reset_index(drop=True)
1
GROUPED_DF.head()
playerid
player_name
errors
bip
0
abrej003
Jose Abreu
20
1864
1
adamm002
Matt Adams
6
834
2
adrie001
Ehire Adrianza
2
533
3
aguij001
Jesus Aguilar
2
551
4
ahmen001
Nick Ahmed
12
1101
1
GROUPED_DF.describe()
errors
bip
count
354.000000
354.000000
mean
12.991525
1129.059322
std
6.447648
428.485467
min
1.000000
503.000000
25%
8.000000
747.250000
50%
12.000000
1112.000000
75%
17.000000
1475.750000
max
37.000000
2102.000000
I’ve identified 354 players who have enough BIP for me to estimate how frequently they hit into errors.
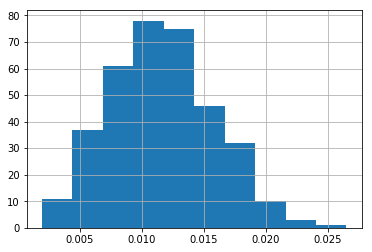
Below, I plot how the likelihood of hitting into errors is distributed.
The question is whether someone who has hit into errors in 2% of their BIP is more likely to hit into an error than someone who has hit into errors in 0.5% of their BIP (or is this all just random variation).
To try and estimate this, I treat each BIP as a Bernoulli trial. Hitting into an error is a “success”. I use a Binomial distribution to model the number of “successes”. I would like to know if different players are more or less likely to hit into errors. To do this, I model each player as having their own Binomial distribution and ask whether p (the probability of success) differs across players.
To answer this question, I could use a chi square contingency test but this would only tell me whether players differ at all and not which players differ.
The traditional way to identify which players differ is to do pairwise comparisons, but this would result in TONS of comparisons making false positives all but certain.
Another option is to harness Bayesian statistics and build a Hierarchical Beta-Binomial model. The intuition is that each player’s probability of hitting into an error is drawn from a Beta distribution. I want to know whether these Beta distributions are different. I then assume I can best estimate a player’s Beta distribution by using that particular player’s data AND data from all players together.
The model is built so that as I accrue data about a particular player, I will trust that data more and more, relying less and less on data from all players. This is called partial pooling. Here’s a useful explanation.
I largely based my analysis on this tutorial. Reference the tutorial for an explanation of how I choose my priors. I ended up using a greater lambda value (because the model sampled better) in the Exponential prior, and while this did lead to more extreme estimates of error likelihood, it didn’t change the basic story.
The most challenging parameter to fit is kappa which modulates for the variance in the likelihood to hit into an error. I take a look at it to make sure things look as expected.
1
pm.summary(trace,varnames=["kappa"])
mean
sd
mc_error
hpd_2.5
hpd_97.5
n_eff
Rhat
kappa
927.587178
141.027597
4.373954
657.066554
1201.922608
980.288914
1.000013
1
pm.traceplot(trace,varnames=['kappa']);
I can also look at phi, the estimated global likelihood to hit into an error.
1
pm.traceplot(trace,varnames=['phi']);
Finally, I can look at how all players vary in their likelihood to hit into an error.
1
pm.traceplot(trace,varnames=['rates']);
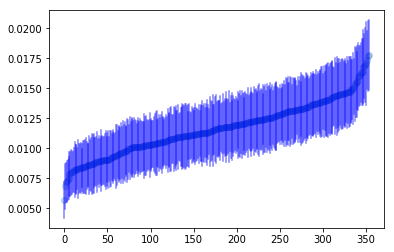
Obviously, the above plot is a lot to look at it, so let’s order players by how likely the model believes they are to hit in an error.
It looks to me like players who hit more ground balls are more likely to hit into an error than players who predominately hits fly balls and line-drives. This makes sense since infielders make more errors than outfielders.
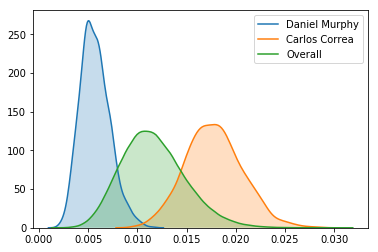
Using the posterior distribution of estimated likelihoods to hit into an error, I can assign a probability to whether Carlos Correa is more likely to hit into an error than Daniel Murphy.
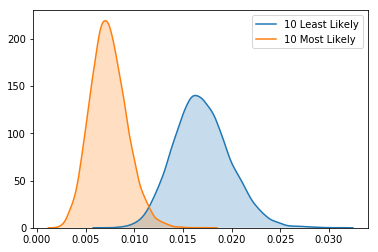
Finally, I can look exclusively at how the posterior distributions of the ten most likely and 10 least likely players to hit into an error compare.
12
sns.kdeplot(trace['rates',1000:][:,[x[2]forxinsorted_means_se[-10:]]].flatten(),shade=True,label="10 Least Likely");sns.kdeplot(trace['rates',1000:][:,[x[2]forxinsorted_means_se[:10]]].flatten(),shade=True,label="10 Most Likely");
All in all, this analysis makes it obvious that some players are more likely to hit into errors than other players. This is probably driven by how often players hit ground balls.
You could summarize this post as “you will never regret good code practices” or “no project is too small for good code practices”.
You might think these recommendations are not worth the time when a project seems small, but projects often grow over time. If you use good practices from the start, you will reduce the technical debt your project accrues over time.
Here’s my list of coding Data Science lessons learned the hard way.
You will never regret using git.
You might think, “this project/query is just 15 minutes of code and I will never think about it again”. While this might be true, it often is not. If your project/query is useful, people will ask for it again with slight tweaks. With each ask, the project grows a little. By using git, you persist the project at all change points, acknowledge that the project will change over time, and prepare for multiple contributors.
Even if you never use these features, I’ve found that simply using git encourages other good practices.
Also, remember git can rescue you when things go wrong!
You will never regret good documentation.
Again, you might think, “this project is so tiny and simple, how could I ever forget how it works??”. You will forget. Or another contributor will appreciate documentation.
The numpy documentation framework is great when working in python. Its integration with sphinx can save you a lot of time when creating non-code documentation.
I recently started documenting not only what the code is doing, but the business rule dictating what the code should do. Having both lets contributors know not only know the how of the code but also the why.
You will never regret building unit-tests.
Again, this might feel like over-kill in small projects, but even small projects have assumptions that should be tested. This is especially true when you add new features after stepping away from a project. By including unit-tests, you assure yourself that existing features did not break, making those pushes to production less scary.
Take the time to build infrastructure for gathering/generating sample/fake data.
I’ve found myself hesitant to build unit-tests because it’s hard to acquire/generate useful sample/fake data. Do not let this be a blocker to good code practices! Take the time to build infrastructure that makes good code practices easy.
This could mean taking the time to write code for building fake data. This could mean taking the time to acquire useful sample data. Maybe it’s both! Take the time to do it. You will not regret making it easy to write tests.
You will always find a Makefile useful.
Once you’ve built infrastructure for acquiring fake or sample data, you will need a way to bring this data into your current project. I’ve found Makefiles useful for this sort of thing. You can define a command that will download some sample data from s3 (or wherever) and save it to your repo (but don’t track these files on git!).
This way all contributors will have common testing data, stored outside of git, and can acquire this data with a single, easy to remember, command.
MakeFiles are also great for installing or saving a project’s dependencies.
Know your project’s dependencies.
Code ecosystems change over time. When you revisit a project after a break, the last thing you want is to guess what code dependencies have broken.
It doesn’t matter whether you save your project’s dependencies as a anaconda environment, a requirements file, virtualenv, a docker image, whatever. Just make sure to save it. Any future contributors (including yourself!!) will thank you.
Most these individual points seem obvious. The overarching point is no project is too small for good code practices. Sure you might think, oh this is just a single query, but you will run that query again, or another member of your team will! While you shouldn’t build a repo for each query, building a repo for different sets of queries is not a bad idea.
I recently found myself wondering if some baseball players are more likely to hit into errors than others. In theory, the answer should be “no” since fielders produce errors regardless of who is hitting. Nonetheless, it’s also possible that some hitters “force” errors by hitting the ball harder or running to first base faster.
In order to evaluate this possibility, I found play-by-play data on retrosheet.org. This data contains row by row data describing each event (e.g., a hit, stolen base etc) in a baseball game. I’ve posted this analysis on github and will walk through it here.
The user is expected to input what year’s data they want. I write the code’s output for the year 2018 as comments. The code starts by downloading and unzipping the data.
The unzipped data contain play-by-play data in files with the EVN or EVA extensions. Each team’s home stadium has its own file. I combine all the play-by play eveSSplants (.EVN and .EVA files) into a single file. I then remove all non batting events (e.g., balk, stolen base etc).
I also combine all the roster files (.ROS) into a single file.
1234567891011121314151617
# export playbyplay to single filemkdir processed_data/${YEAR}/
find raw_data/${YEAR}/ -regex '.*EV[A|N]'|\ xargs grep play > \ ./processed_data/${YEAR}/playbyplay.out
# get all plate appearances from data (and hitter). remove all non plate appearance rowscat ./processed_data/${YEAR}/playbyplay.out |\ awk -F',''{print $4","$7}'|\ grep -Ev ',[A-Z]{3}[0-9]{2}'|\ grep -Ev ',(NP|BK|CS|DI|OA|PB|WP|PO|POCS|SB|FLE)' > \ ./processed_data/${YEAR}/batters.out
# one giant roster filefind raw_data/${YEAR}/ -name '*ROS'|\ xargs awk -F',''{print $1" "$2" "$3}' > \ ./processed_data/${YEAR}/players.out
In this next few code blocks I print some data just to see what I am working with. For instance, I print out players with the most plate appearances. I was able to confirm these numbers with baseball-reference. This operation requires me to groupby player and count the rows. I join this file with the roster file to get player’s full names.
1234567891011121314151617181920212223
echo"---------PLAYERS WITH MOST PLATE APPEARANCES----------"cat ./processed_data/${YEAR}/batters.out |\ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}'|\ sort -k2 -nr |\ head > \ ./processed_data/${YEAR}/most_pa.out
join <(sort -k 1 ./processed_data/${YEAR}/players.out) <(sort -k 1 ./processed_data/${YEAR}/most_pa.out)|\ uniq |\ sort -k 4 -nr |\ head |\ awk '{print $3", "$2", "$4}'#---------PLAYERS WITH MOST PLATE APPEARANCES----------#Francisco, Lindor, 745#Trea, Turner, 740#Manny, Machado, 709#Cesar, Hernandez, 708#Whit, Merrifield, 707#Freddie, Freeman, 707#Giancarlo, Stanton, 706#Nick, Markakis, 705#Alex, Bregman, 705#Marcus, Semien, 703
Here’s the players with the most hits. Notice that I filter out all non-hits in the grep, then group by player.
123456789101112131415161718
echo"---------PLAYERS WITH MOST HITS----------"cat ./processed_data/${YEAR}/batters.out |\ grep -E ',(S|D|T|HR)'|\ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}'|\ sort -k2 -nr |\ head
#---------PLAYERS WITH MOST HITS----------#merrw001 192#freef001 191#martj006 188#machm001 188#yelic001 187#markn001 185#castn001 185#lindf001 183#peraj003 182#blacc001 182
Here’s the players with the most at-bats.
12345678910111213141516171819
echo"---------PLAYERS WITH MOST AT BATS----------"cat ./processed_data/${YEAR}/batters.out |\ grep -Ev 'SF|SH'|\ grep -E ',(S|D|T|HR|K|[0-9]|E|DGR|FC)'|\ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}' > \ ./processed_data/${YEAR}/abs.out
cat ./processed_data/${YEAR}/abs.out | sort -k2 -nr | head
#---------PLAYERS WITH MOST AT BATS----------#turnt001 664#lindf001 661#albio001 639#semim001 632#peraj003 632#merrw001 632#machm001 632#blacc001 626#markn001 623#castn001 620
And, finally, here’s the players who hit into the most errors.
12345678910111213141516171819
echo"---------PLAYERS WHO HIT INTO THE MOST ERRORS----------"cat ./processed_data/${YEAR}/batters.out |\ grep -Ev 'SF|SH'|\ grep ',E[0-9]'|\ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}' > \ ./processed_data/${YEAR}/errors.out
cat ./processed_data/${YEAR}/errors.out | sort -k2 -nr | head
#---------PLAYERS WHO HIT INTO THE MOST ERRORS----------#gurry001 13#casts001 13#baezj001 12#goldp001 11#desmi001 11#castn001 10#bogax001 10#andum001 10#turnt001 9#rojam002 9
Because players with more at-bats hit into more errors, I need to take the number of at-bats into account. I also filter out all players with less than 250 at bats. I figure we only want players with lots of opportunities to create errors.
123456789101112131415161718
echo"---------PLAYERS WITH MOST ERRORS PER AT BAT----------"join -e"0" -a1 -a2 <(sort -k 1 ./processed_data/${YEAR}/abs.out) -o 0 1.2 2.2 <(sort -k 1 ./processed_data/${YEAR}/errors.out)|\ uniq |\ awk -v OFS=', ''$2 > 250 {print $1, $3, $2, $3/$2}' > \ ./processed_data/${YEAR}/errors_abs.out
cat ./processed_data/${YEAR}/errors_abs.out | sort -k 4 -nr | head
#---------PLAYERS WITH MOST ERRORS PER AT BAT----------#pereh001, 8, 316, 0.0253165#gurry001, 13, 537, 0.0242086#andre001, 9, 395, 0.0227848#casts001, 13, 593, 0.0219224#desmi001, 11, 555, 0.0198198#baezj001, 12, 606, 0.019802#garca003, 7, 356, 0.0196629#bogax001, 10, 512, 0.0195312#goldp001, 11, 593, 0.0185497#iglej001, 8, 432, 0.0185185
At-bats is great but even better is to remove strike-outs and just look at occurences when a player hit the ball into play. I remove all players with less than 450 balls hit into play which limits us to just 37 players but the players have enough reps to make the estimates more reliable.
1234567891011121314151617181920212223
echo"---------PLAYERS WITH MOST ERRORS PER BALL IN PLAY----------"cat ./processed_data/${YEAR}/batters.out |\ grep -Ev 'SF|SH'|\ grep -E ',(S|D|T|HR|[0-9]|E|DGR|FC)'|\ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}' > \ ./processed_data/${YEAR}/bip.out
join -e"0" -a1 -a2 <(sort -k 1 ./processed_data/${YEAR}/bip.out) -o 0 1.2 2.2 <(sort -k 1 ./processed_data/${YEAR}/errors.out)|\ uniq |\ awk -v OFS=', ''$2 > 450 {print $1, $3, $2, $3/$2}' > \ ./processed_data/${YEAR}/errors_bip.out
cat ./processed_data/${YEAR}/errors_bip.out | sort -k 4 -nr | head
#---------PLAYERS WITH MOST ERRORS PER BALL IN PLAY----------#casts001, 13, 469, 0.0277186#gurry001, 13, 474, 0.0274262#castn001, 10, 469, 0.021322#andum001, 10, 476, 0.0210084#andeb006, 9, 461, 0.0195228#turnt001, 9, 532, 0.0169173#simma001, 8, 510, 0.0156863#lemad001, 7, 451, 0.0155211#sancc001, 7, 462, 0.0151515#freef001, 7, 486, 0.0144033
Now we have some data. In future posts I will explore how we can use statistics to evaluate whether some players are more likely to hit into errors than others.
Check out the companion post that statistically explores this question.
I’ve touched on this in past posts, but wanted to write a post specifically describing the power of what I call complex aggregations in PySpark.
The idea is that you have have a data request which initially seems to require multiple different queries, but using ‘complex aggregations’ you can create the requested data using a single query (and a single shuffle).
Let’s say you have a dataset like the following. You have one column (id) which is a unique key for each user, another column (group) which expresses the group that each user belongs to, and finally (value) which expresses the value of each customer. I apologize for the contrived example.
Let’s say someone wants the average value of group a, b, and c, AND the average value of users in group a OR b, the average value of users in group b OR c AND the value of users in group a OR c. Adds a wrinkle, right? The ‘or’ clauses prevent us from using a simple groupby, and we don’t want to have to write 4 different queries.
Using complex aggregations, we can access all these different conditions in a single query.
Predeval is software designed to help you identify changes in a model’s output.
For instance, you might be tasked with building a model to predict churn. When you deploy this model in production, you have to wait to learn which users churned in order to know how your model performed. While Predeval will not free you from this wait, it can provide initial signals as to whether the model is producing reasonable (i.e., expected) predictions. Unexpected predictions might reflect a poor performing model. They also might reflect a change in your input data. Either way, something has changed and you will want to investigate further.
Using predeval, you can detect changes in model output ASAP. You can then use python’s libraries to build a surrounding alerting system that will signal a need to investigate. This system should give you additional confidence that your model is performing reasonably. Here’s a post where I configure an alerting system using python, mailutils, and postfix (although the alerting system is not built around predeval).
Predeval operates by forming expectations about what your model’s outputs will look like. For example, you might give predeval the model’s output from a validation dataset. Predeval will then compare new outputs to the outputs produced by the validation dataset, and will report whether it detects a difference.
Predeval works with models producing both categorical and continuous outputs.
Here’s an example of predeval with a model producing categorical outputs. Predeval will (by default) check whether all expected output categories are present, and whether the output categories occur at their expected frequencies (using a Chi-square test of independence of variables in a contingency table).
Here’s an example of predeval with a model producing continuous outputs. Predeval will (by default) check whether the new output have a minimum lower than expected, a maximum greater than expected, a different mean, a different standard deviation, and whether the new output are distributed as expected (using a Kolmogorov-Smirnov test)