In basketball, we typically talk about 5 positions: point guard, shooting guard, small forward, power forward, and center. Based on this, one might expect NBA players to fall into 5 distinct groups- Point guards perform similar to other point guards, shooting guards perform similar to other shooting guards, etc. Is this the case? Do NBA players fall neatly into position groups?
To answer this question, I will look at how NBA players “group” together. For example, there might be a group of players who collect lots of rebounds, shoot poorly from behind the 3 point line, and block lots of shots. I might call these players forwards. If we allow player performance to create groups, what will these groups look like?
To group players, I will use k-means clustering (https://en.wikipedia.org/wiki/K-means_clustering).
When choosing a clustering algorithm, its important to think about how the clustering algorithm defines clusters. k-means minimizes the distance between data points (players in my case) and the center of K different points. Because distance is between the cluster center and a given point, k-means assumes clusters are spherical. When thinking about clusters of NBA players, do I think these clusters will be spherical? If not, then I might want try a different clustering algorithm.
For now, I will assume generally spherical clusters and use k-means. At the end of this post, I will comment on whether this assumption seems valid.
1 2 3 4 5 6 7 | |
We need data. Collecting the data will require a couple steps. First, I will create a matrix of all players who ever played in the NBA (via the NBA.com API).
1 2 3 4 5 6 | |
In the 1979-1980 season, the NBA started using the 3-point line. The 3-point has dramatically changed basketball, so players performed different before it. While this change in play was not instantaneous, it does not make sense to include players before the 3-point line.
1 2 | |
I have a list of all the players after 1979, but I want data about all these players. When grouping the players, I am not interested in how much a player played. Instead, I want to know HOW a player played. To remove variability associated with playing time, I will gather data that is standardized for 36 minutes of play. For example, if a player averages 4 points and 12 minutes a game, this player averages 12 points per 36 minutes.
Below, I have written a function that will collect every player’s performance per 36 minutes. The function collects data one player at a time, so its VERY slow. If you want the data, it can be found on my github (https://github.com/dvatterott/nba_project).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
1
| |
Index([u'PLAYER_ID', u'LEAGUE_ID', u'TEAM_ID', u'GP', u'GS',
u'MIN', u'FGM', u'FGA', u'FG_PCT', u'FG3M',
u'FG3A', u'FG3_PCT', u'FTM', u'FTA', u'FT_PCT',
u'OREB', u'DREB', u'REB', u'AST', u'STL',
u'BLK', u'TOV', u'PF', u'PTS'],
dtype='object')
Great! Now we have data that is scaled for 36 minutes of play (per36 data) from every player between 1979 and 2016. Above, I printed out the columns. I don’t want all this data. For instance, I do not care about how many minutes a player played. Also, some of the data is redundant. For instance, if I know a player’s field goal attempts (FGA) and field goal percentage (FG_PCT), I can calculate the number of made field goals (FGM). I removed the data columns that seem redundant. I do this because I do not want redundant data exercising too much influence on the grouping process.
Below, I create new data columns for 2 point field goal attempts and 2 point field goal percentage. I also remove all players who played less than 50 games. I do this because these players have not had the opportunity to establish consistent performance.
1 2 3 4 5 6 7 | |
It’s always important to visualize the data, so lets get an idea what we’re working with!
The plot below is called a scatter matrix. This type of plot will appear again, so lets go through it carefully. Each subplot has the feature (stat) labeled on its row which serves as its y-axis. The column feature serves as the x-axis. For example the subplot in the second column of the first row plots 3-point field goal attempts by 3-point field goal percentage. As you can see, players that have higher 3-point percentages tend to take more 3-pointers… makes sense.
On the diagonals, I plot the Kernel Density Estimation for the sample histogram. More players fall into areas where where the line is higher on the y-axis. For instance, no players shoot better than ~45% from behind the 3 point line.
One interesting part about scatter matrices is the plots below the diagonal are a reflection of the plots above the diagonal. For example, the data in the second column of the first row and the first column of the second row are the same. The only difference is the axes have switched.
1 2 3 | |
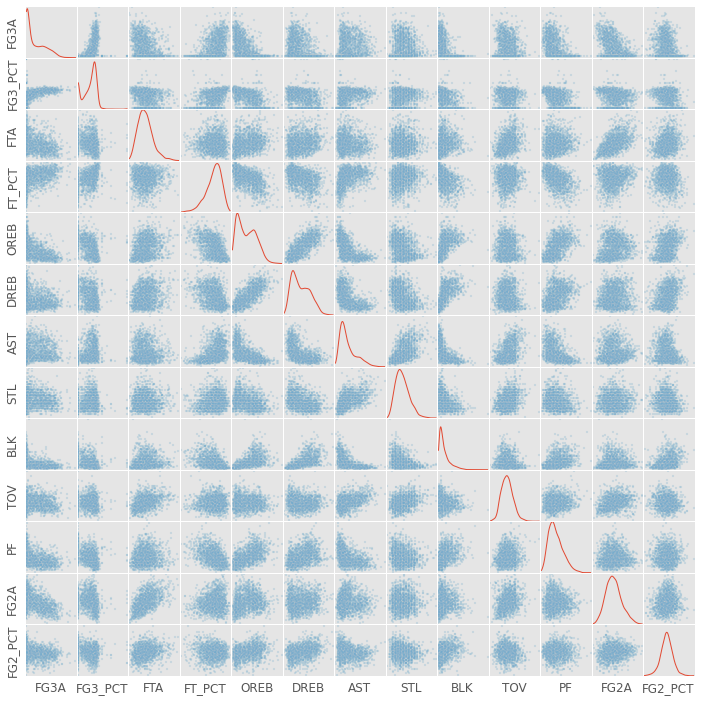
There are a couple things to note in the graph above. First, there’s a TON of information there. Second, it looks like there are some strong correlations. For example, look at the subplots depicting offensive rebounds by defensive rebounds.
While I tried to throw out redundant data, I clearly did not throw out all redundant data. For example, players that are good 3-point shooters are probably also good free throw shooters. These players are simply good shooters, and being a good shooter contributes to multiple data columns above.
When I group the data, I do not want an ability such as shooting to contribute too much. I want to group players equally according to all their abilities. Below I use a PCA to seperate variance associated with the different “components” (e.g., shooting ability) of basketball performance.
For an explanation of PCA I recommend this link - https://georgemdallas.wordpress.com/2013/10/30/principal-component-analysis-4-dummies-eigenvectors-eigenvalues-and-dimension-reduction/.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
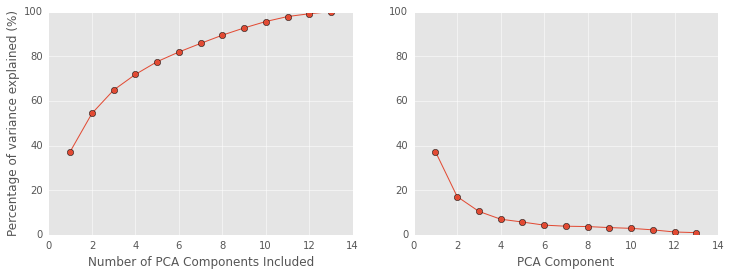
On the left, I plot the amount of variance explained after including each additional PCA component. Using all the components explains all the variability, but notice how little the last few components contribute. It doesn’t make sense to include a component that only explains 1% of the variability…but how many components to include!?
I chose to include the first 5 components because no component after the 5th explained more than 5% of the data. This part of the analysis is admittedly arbitrary, but 5% is a relatively conservative cut-off.
Below is the fun part of the data. We get to look at what features contribute to the different principle components.
- Assists and 3-point shooting contribute to the first component. I will call this the Outside Skills component.
- Free throw attempts, assists, turnovers and 2-point field goals contribute to the second component. I will call this the Rim Scoring component.
- Free throw percentage and 2-point field goal percentage contribute to the third component. I will call this the Pure Points component.
- 2-point field goal percentage and steals contribute to the fourth component. I will call this the Defensive Big Man component.
- 3-point shooting and free throws contribute to the fifth component. I will call this the Dead Eye component.
One thing to keep in mind here is that each component explains less variance than the last. So while 3 point shooting contributes to both the 1st and 5th component, more 3 point shooting variability is probably explained by the 1st component.
It would be great if we had a PCA component that was only shooting and another that was only rebounding since we typically conceive these to be different skills. Yet, there are multiple aspects of each skill. For example, a 3-point shooter not only has to be a dead-eye shooter, but also has to find ways to get open. Additionally, being good at “getting open” might be something akin to basketball IQ which would also contribute to assists and steals!
1 2 3 | |
Cool, we have our 5 PCA components. Now lets transform the data into our 5 component PCA space (from our 13 feature space - e.g., FG3A, FG3_PCT, ect.). To do this, we give each player a score on each of the 5 PCA components.
Next, I want to see how players cluster together based on their scores on these components. First, let’s investigate how using more or less clusters (i.e., groups) explains different amounts of variance.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
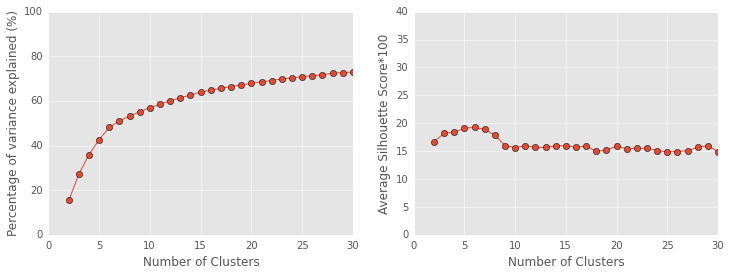
As you can in the left hand plot, adding more clusters explains more of the variance, but there are diminishing returns. Each additional cluster explains a little less data than the last (much like each PCA component explained less variance than the previous component).
The particularly intersting point here is the point where the second derivative is greatest, when the amount of change changes the most (the elbow). The elbow occurs at the 6th cluster.
Perhaps not coincidently, 6 clusters also has the highest silhouette score (right hand plot). The silhouette score computes the average distance between a player and all other players in this player’s cluster. It then divides this distance by the distance between this player and all players in the next nearest cluster. Silhouette scores range between -1 and 1 (where negative one means the player is in the wrong cluster, 0 means the clusters completely overlap, and 1 means the clusters are extermely well separated).
Six clusters has the highest silhouette score at 0.19. 0.19 is not great, and suggests a different clustering algorithm might be better. More on this later.
Because 6 clusters is the elbow and has the highest silhouette score, I will use 6 clusters in my grouping analysis. Okay, now that I decided on 6 clusters lets see what players fall into what clusters!
1 2 3 4 5 6 7 8 9 10 | |
Awesome. Now lets see how all the clusters look. These clusters were created in 5 dimensional space, which is not easy to visualize. Below I plot another scatter matrix. The scatter matrix allows us to visualize the clusters in different 2D combinations of the 5D space.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
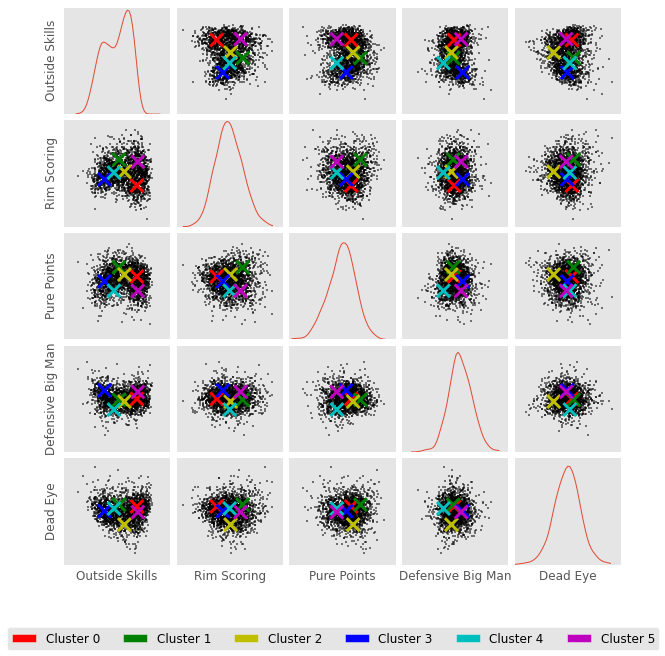
In this plot above. I mark the center of a given cluster with an X. For example, Cluster 0 and Cluster 5 are both high in outside skills. Cluster 5 is also high in rim scoring, but low in pure points.
Below I look at the players in each cluster. The first thing I do is identify the player closest to the cluster’s center. I call this player the prototype. It is the player that most exemplifies a cluster.
I then show a picture of this player because… well I wanted to see who these players were. I print out this player’s stats and the cluster’s centroid location. Finally, I print out the first ten players in this cluster. This is the first ten players alphabetically. Not the ten players closest to cluster center.
1 2 3 4 5 6 7 8 9 10 11 | |

| Outside Skills | Rim Scoring | Pure Points | Defensive Big Man | Dead Eye |
|---|---|---|---|---|
| 0.830457 | -0.930833 | 0.28203 | -0.054093 | 0.43606 |
16 Afflalo, Arron
20 Ainge, Danny
40 Allen, Ray
46 Alston, Rafer
50 Aminu, Al-Farouq
53 Andersen, David
54 Anderson, Alan
56 Anderson, Derek
60 Anderson, James
63 Anderson, Kyle
Name: Name, dtype: object
First, let me mention that cluster number is a purely categorical variable. Not ordinal. If you run this analysis, you will likely create clusters with similar players, but in a different order. For example, your cluster 1 might be my cluster 0.
Cluster 0 has the most players (25%; about 490 of the 1965 in this cluster analysis) and is red in the scatter matrix above.
Cluster 0 players are second highest in outside shooting (in the table above you can see their average score on the outside skills component is 0.83). These players are lowest in rim scoring (-0.93), so they do not draw many fouls - they are basically the snipers from the outside.
The prototype is Lloyd Daniels who takes a fair number of 3s. I wouldn’t call 31% a dominant 3-point percentage, but its certainly not bad. Notably, Lloyd Daniels doesn’t seem to do much but shoot threes, as 55% of his shots come from the great beyond.
Cluster 0 notable players include Andrea Bargnani, JJ Barea, Danilo Gallinari, and Brandon Jennings. Some forwards. Some Guards. Mostly good shooters.
On to Cluster 1… I probably should have made a function from this code, but I enjoyed picking the players pictures too much.
1 2 3 4 5 6 7 8 | |

| Outside Skills | Rim Scoring | Pure Points | Defensive Big Man | Dead Eye |
|---|---|---|---|---|
| -0.340177 | 1.008111 | 1.051622 | -0.150204 | 0.599516 |
1 Abdul-Jabbar, Kareem
4 Abdur-Rahim, Shareef
9 Adams, Alvan
18 Aguirre, Mark
75 Antetokounmpo, Giannis
77 Anthony, Carmelo
85 Arenas, Gilbert
121 Baker, Vin
133 Barkley, Charles
148 Bates, Billyray
Name: Name, dtype: object
Cluster 1 is green in the scatter matrix and includes about 14% of players.
Cluster 1 is highest on the rim scoring, pure points, and Dead Eye components. These players get the ball in the hoop.
Christian Laettner is the prototype. He’s a solid scoring forward.
Gilbert Arenas stands out in the first ten names as I was tempted to think of this cluster as big men, but it really seems to be players who shoot, score, and draw fouls.
Cluster 1 Notable players include James Harden,Kevin Garnet, Kevin Durant, Tim Duncan, Kobe, Lebron, Kevin Martin, Shaq, Anthony Randolph??, Kevin Love, Derrick Rose, and Michael Jordan.
1 2 3 4 5 6 7 8 | |

| Outside Skills | Rim Scoring | Pure Points | Defensive Big Man | Dead Eye |
|---|---|---|---|---|
| 0.013618 | 0.101054 | 0.445377 | -0.347974 | -1.257634 |
2 Abdul-Rauf, Mahmoud
3 Abdul-Wahad, Tariq
5 Abernethy, Tom
10 Adams, Hassan
14 Addison, Rafael
24 Alarie, Mark
27 Aldridge, LaMarcus
31 Alexander, Courtney
35 Alford, Steve
37 Allen, Lavoy
Name: Name, dtype: object
Cluster 2 is yellow in the scatter matrix and includes about 17% of players.
Lots of big men who are not outside shooters and don’t draw many fouls. These players are strong 2 point shooters and free throw shooters. I think of these players as mid-range shooters. Many of the more recent Cluster 2 players are forwards since mid-range guards do not have much of a place in the current NBA.
Cluster 2’s prototype is Doug West. Doug West shoots well from the free throw line and on 2-point attempts, but not the 3-point line. He does not draw many fouls or collect many rebounds.
Cluster 2 noteable players include LaMarcus Aldridge, Tayshaun Prince, Thaddeus Young, and Shaun Livingston
1 2 3 4 5 6 7 8 | |

| Outside Skills | Rim Scoring | Pure Points | Defensive Big Man | Dead Eye |
|---|---|---|---|---|
| -1.28655 | -0.467105 | -0.133546 | 0.905368 | 0.000679 |
7 Acres, Mark
8 Acy, Quincy
13 Adams, Steven
15 Adrien, Jeff
21 Ajinca, Alexis
26 Aldrich, Cole
34 Alexander, Victor
45 Alston, Derrick
51 Amundson, Lou
52 Andersen, Chris
Name: Name, dtype: object
Cluster 3 is blue in the scatter matrix and includes about 16% of players.
Cluster 3 players do not have outside skills such as assists and 3-point shooting (they’re last in outside skills). They do not draw many fouls or shoot well from the free throw line. These players do not shoot often, but have a decent shooting percentage. This is likely because they only shoot when wide open next to the hoop.
Cluster 3 players are highest on the defensive big man component. They block lots of shots and collect lots of rebounds.
The Cluster 3 prototype is Kelvin Cato. Cato is not and outside shooter and he only averages 7.5 shots per 36, but he makes these shots at a decent clip. Cato averages about 10 rebounds per 36.
Notable Cluster 3 players include Andrew Bogut, Tyson Chandler, Andre Drummond, Kawahi Leonard??, Dikembe Mutumbo, and Hassan Whiteside.
1 2 3 4 5 6 7 8 | |

| Outside Skills | Rim Scoring | Pure Points | Defensive Big Man | Dead Eye |
|---|---|---|---|---|
| -0.668445 | 0.035927 | -0.917479 | -1.243347 | 0.244897 |
0 Abdelnaby, Alaa
17 Ager, Maurice
28 Aleksinas, Chuck
33 Alexander, Joe
36 Allen, Jerome
48 Amaechi, John
49 Amaya, Ashraf
74 Anstey, Chris
82 Araujo, Rafael
89 Armstrong, Brandon
Name: Name, dtype: object
Cluster 4 is cyan in the scatter matrix above and includes the least number of players (about 13%).
Cluster 4 players are not high on outsize skills. They are average on rim scoring. They do not score many points, and they don’t fill up the defensive side of the stat sheet. These players don’t seem like all stars.
Looking at Doug Edwards’ stats - certainly not a 3-point shooter. I guess a good description of cluster 4 players might be … NBA caliber bench warmers.
Cluster 4’s notable players include Yi Jianlian and Anthony Bennet….yeesh
1 2 3 4 5 6 7 8 9 | |

| Outside Skills | Rim Scoring | Pure Points | Defensive Big Man | Dead Eye |
|---|---|---|---|---|
| 0.890984 | 0.846109 | -0.926444 | 0.735306 | -0.092395 |
12 Adams, Michael
30 Alexander, Cory
41 Allen, Tony
62 Anderson, Kenny
65 Anderson, Mitchell
78 Anthony, Greg
90 Armstrong, Darrell
113 Bagley, John
126 Banks, Marcus
137 Barrett, Andre
Name: Name, dtype: object
Cluster 5 is magenta in the scatter matrix and includes 16% of players.
Cluster 5 players are highest in outside skills and second highest in rim scoring yet these players are dead last in pure points. It seems they score around the rim, but do not draw many fouls. They are second highest in defensive big man.
Gerald Henderson Sr is the prototype. Henderson is a good 3 point and free throw shooter but does not draw many fouls. He has lots of assists and steals.
Of interest mostly because it generates an error in my code, Gerald Henderson Jr is in cluster 2 - the mid range shooters.
Notable cluster 5 players include Mugsy Bogues, MCW, Jeff Hornacek, Magic Johnson, Jason Kidd, Steve Nash, Rajon Rando, John Stockton. Lots of guards.
In the cell below, I plot the percentage of players in each cluster.
1 2 3 4 | |
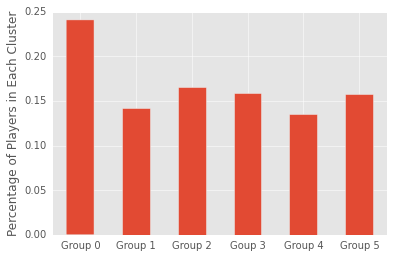
I began this post by asking whether player positions is the most natural way to group NBA players. The clustering analysis here suggests not.
Here’s my take on the clusters: Cluster 0 is pure shooters, Cluster 1 is talented scorers, Cluster 2 is mid-range shooters, Cluster 3 is defensive big-men, Cluster 4 is bench warmers, Cluster 5 is distributors. We might call the “positions” shooters, scorers, rim protectors, and distributors.
It’s possible that our notion of position comes more from defensive performance than offensive. On defense, a player must have a particular size and agility to guard a particular opposing player. Because of this, a team will want a range of sizes and agility - strong men to defend the rim and quick men to defend agile ball carriers. Box scores are notoriously bad at describing defensive performance. This could account for the lack of “positions” in my cluster.
I did not include player height and weight in this analysis. I imagine height and weight might have made clusters that resemble the traditional positions. I chose to not include height and weight because these are player attributes; not player performance.
After looking through all the groups one thing that stands out to me is the lack of specialization. For example we did not find a single cluster of incredible 3-point shooters. Cluster 1 includes many great shooters, but it’s not populated exclusively by great shooters. It would be interesting if adding additional clusters to the analysis could find more specific clusters such as big-men that can shoot from the outside (e.g., Dirk) or high-volume scorers (e.g., Kobe).
I tried to list some of the aberrant cluster choices in the notable players to give you an idea for the amount of error in the clustering. These aberrant choices are not errors, they are simply an artifact of how k-means defines clusters. Using a different clustering algorithm would produce different clusters. On that note, the silhouette score of this clustering model is not great, yet the clustering algorithm definitely found similar players, so its not worthless. Nonetheless, clusters of NBA players might not be spherical. This would prevent a high silhouette score. Trying a different algorithm without the spherical clusters assumption would definitely be worthwhile.
Throughout this entire analysis, I was tempted to think about group membership, as a predictor of a player’s future performance. For instance, when I saw Karl Anthony Towns in the same cluster as Kareem Abdul-Jabbar, I couldn’t help but think this meant good things for Karl Anthony Towns. Right now, this doesn’t seem justified. No group included less than 10% of players so not much of an oppotunity for a uniformly “star” group to form. Each group contained some good and some bad players. Could more clusters change this? I plan on examining whether more clusters can improve the clustering algorithm’s ability to find clusters of exclusively quality players. If it works, I’ll post it here.