As a huge t-wolves fan, I’ve been curious all year by what we can infer from Karl-Anthony Towns’ great rookie season. To answer this question, I’ve create a simple linear regression model that uses rookie year performance to predict career performance.
Many have attempted to predict NBA players’ success via regression style approaches. Notable models I know of include Layne Vashro’s model which uses combine and college performance to predict career performance. Layne Vashro’s model is a quasi-poisson GLM. I tried a similar approach, but had the most success when using ws/48 and OLS. I will discuss this a little more at the end of the post.
A jupyter notebook of this post can be found on my github.
1 2 3 4 5 6 7 8 9 | |
I collected all the data for this project from basketball-reference.com. I posted the functions for collecting the data on my github. The data is also posted there. Beware, the data collection scripts take awhile to run.
This data includes per 36 stats and advanced statistics such as usage percentage. I simply took all the per 36 and advanced statistics from a player’s page on basketball-reference.com.
1 2 | |
The variable I am trying to predict is average WS/48 over a player’s career. There’s no perfect box-score statistic when it comes to quantifying a player’s peformance, but ws/48 seems relatively solid.
1 2 3 4 5 6 7 8 | |
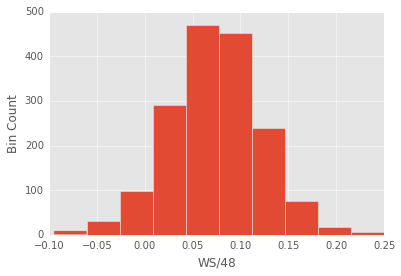
The predicted variable looks pretty gaussian, so I can use ordinary least squares. This will be nice because while ols is not flexible, it’s highly interpretable. At the end of the post I’ll mention some more complex models that I will try.
1 2 3 4 5 6 | |
Above, I remove some predictors from the rookie data. Lets run the regression!
1 2 3 4 5 6 7 8 | |
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.476
Model: OLS Adj. R-squared: 0.461
Method: Least Squares F-statistic: 31.72
Date: Sun, 20 Mar 2016 Prob (F-statistic): 2.56e-194
Time: 15:29:43 Log-Likelihood: 3303.9
No. Observations: 1690 AIC: -6512.
Df Residuals: 1642 BIC: -6251.
Df Model: 47
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const 0.2509 0.078 3.223 0.001 0.098 0.404
x1 -0.0031 0.001 -6.114 0.000 -0.004 -0.002
x2 -0.0004 9.06e-05 -4.449 0.000 -0.001 -0.000
x3 -0.0003 8.12e-05 -3.525 0.000 -0.000 -0.000
x4 1.522e-05 4.73e-06 3.218 0.001 5.94e-06 2.45e-05
x5 0.0030 0.031 0.096 0.923 -0.057 0.063
x6 0.0109 0.019 0.585 0.559 -0.026 0.047
x7 -0.0312 0.094 -0.331 0.741 -0.216 0.154
x8 0.0161 0.027 0.594 0.553 -0.037 0.069
x9 -0.0054 0.018 -0.292 0.770 -0.041 0.031
x10 0.0012 0.007 0.169 0.866 -0.013 0.015
x11 0.0136 0.023 0.592 0.554 -0.031 0.059
x12 -0.0099 0.018 -0.538 0.591 -0.046 0.026
x13 0.0076 0.054 0.141 0.888 -0.098 0.113
x14 0.0094 0.012 0.783 0.433 -0.014 0.033
x15 0.0029 0.002 1.361 0.174 -0.001 0.007
x16 0.0078 0.009 0.861 0.390 -0.010 0.026
x17 -0.0107 0.019 -0.573 0.567 -0.047 0.026
x18 -0.0062 0.018 -0.342 0.732 -0.042 0.029
x19 0.0095 0.017 0.552 0.581 -0.024 0.043
x20 0.0111 0.004 2.853 0.004 0.003 0.019
x21 0.0109 0.018 0.617 0.537 -0.024 0.046
x22 -0.0139 0.006 -2.165 0.030 -0.026 -0.001
x23 0.0024 0.005 0.475 0.635 -0.008 0.012
x24 0.0022 0.001 1.644 0.100 -0.000 0.005
x25 -0.0125 0.012 -1.027 0.305 -0.036 0.011
x26 -0.0006 0.000 -1.782 0.075 -0.001 5.74e-05
x27 -0.0011 0.001 -1.749 0.080 -0.002 0.000
x28 0.0012 0.003 0.487 0.626 -0.004 0.006
x29 0.1824 0.089 2.059 0.040 0.009 0.356
x30 -0.0288 0.025 -1.153 0.249 -0.078 0.020
x31 -0.0128 0.011 -1.206 0.228 -0.034 0.008
x32 -0.0046 0.008 -0.603 0.547 -0.020 0.010
x33 -0.0071 0.005 -1.460 0.145 -0.017 0.002
x34 0.0131 0.012 1.124 0.261 -0.010 0.036
x35 -0.0023 0.001 -2.580 0.010 -0.004 -0.001
x36 -0.0077 0.013 -0.605 0.545 -0.033 0.017
x37 0.0069 0.004 1.916 0.055 -0.000 0.014
x38 -0.0015 0.001 -2.568 0.010 -0.003 -0.000
x39 -0.0002 0.002 -0.110 0.912 -0.005 0.004
x40 -0.0109 0.017 -0.632 0.528 -0.045 0.023
x41 -0.0142 0.017 -0.821 0.412 -0.048 0.020
x42 0.0217 0.017 1.257 0.209 -0.012 0.056
x43 0.0123 0.102 0.121 0.904 -0.188 0.213
x44 0.0441 0.018 2.503 0.012 0.010 0.079
x45 0.0406 0.018 2.308 0.021 0.006 0.075
x46 -0.0410 0.018 -2.338 0.020 -0.075 -0.007
x47 0.0035 0.003 1.304 0.192 -0.002 0.009
==============================================================================
Omnibus: 42.820 Durbin-Watson: 1.966
Prob(Omnibus): 0.000 Jarque-Bera (JB): 54.973
Skew: 0.300 Prob(JB): 1.16e-12
Kurtosis: 3.649 Cond. No. 1.88e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.88e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
There’s a lot to look at in the regression output (especially with this many features). For an explanation of all the different parts of the regression take a look at this post. Below is a quick plot of predicted ws/48 against actual ws/48.
1 2 3 4 | |
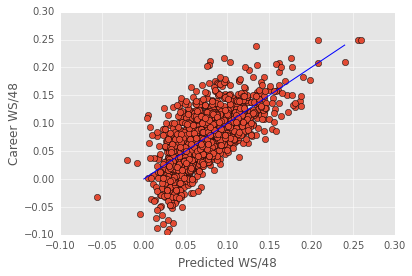
The blue line above is NOT the best-fit line. It’s the identity line. I plot it to help visualize where the model fails. The model seems to primarily fail in the extremes - it tends to overestimate the worst players.
All in all, This model does a remarkably good job given its simplicity (linear regression), but it also leaves a lot of variance unexplained.
One reason this model might miss some variance is there’s more than one way to be a productive basketball player. For instance, Dwight Howard and Steph Curry find very different ways to contribute. One linear regression model is unlikely to succesfully predict both players.
In a previous post, I grouped players according to their on-court performance. These player groupings might help predict career performance.
Below, I will use the same player grouping I developed in my previous post, and examine how these groupings impact my ability to predict career performance.
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 8 | |
See my other post for more details about this clustering procedure.
Let’s see how WS/48 varies across the groups.
1 2 | |
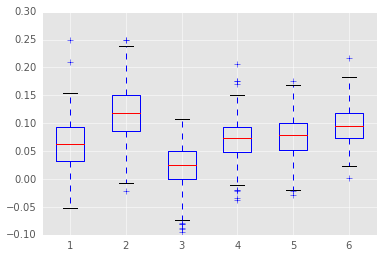
Some groups perform better than others, but there’s lots of overlap between the groups. Importantly, each group has a fair amount of variability. Each group spans at least 0.15 WS/48. This gives the regression enough room to successfully predict performance in each group.
Now, lets get a bit of a refresher on what the groups are. Again, my previous post has a good description of these groups.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
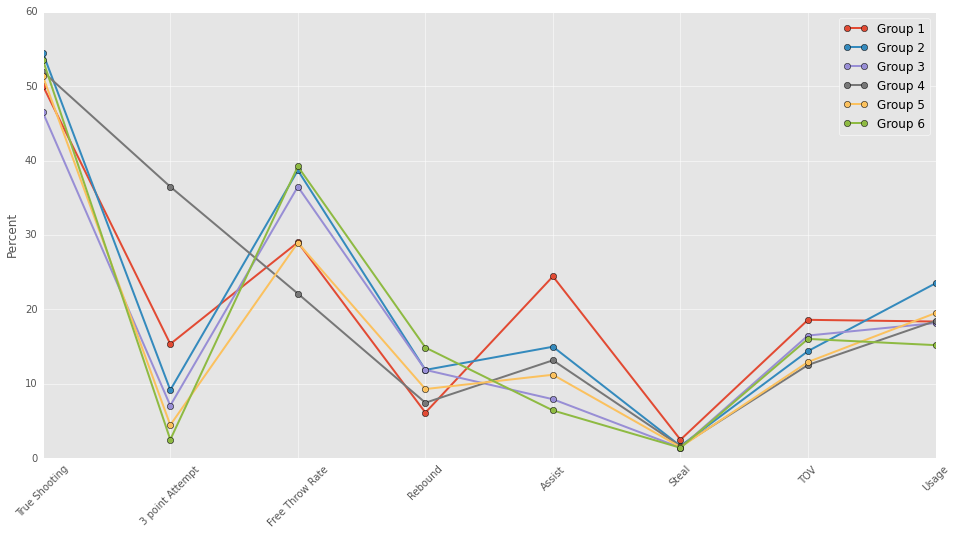
I’ve plotted the groups across a number of useful categories. For information about these categories see basketball reference’s glossary.
Here’s a quick rehash of the groupings. See my previous post for more detail.
- **Group 1:** These are the distributors who shoot a fair number of threes, don't rebound at all, dish out assists, gather steals, and ...turn the ball over.
- **Group 2:** These are the scorers who get to the free throw line, dish out assists, and carry a high usage.
- **Group 3:** These are the bench players who don't score...or do much in general.
- **Group 4:** These are the 3 point shooters who shoot tons of 3 pointers, almost no free throws, and don't rebound well.
- **Group 5:** These are the mid-range shooters who shoot well, but don't shoot threes or draw free throws
- **Group 6:** These are the defensive big men who shoot no threes, rebound lots, and carry a low usage.
On to the regression.
1 2 3 4 5 6 7 8 | |
You might have noticed the giant condition number in the regression above. This indicates significant multicollinearity of the features, which isn’t surprising since I have many features that reflect the same abilities.
The multicollinearity doesn’t prevent the regression model from making accurate predictions, but does it make the beta weight estimates irratic. With irratic beta weights, it’s hard to tell whether the different clusters use different models when predicting career ws/48.
In the following regression, I put the predicting features through a PCA and keep only the first 10 PCA components. Using only the first 10 PCA components keeps the component score below 20, indicating that multicollinearity is not a problem. I then examine whether the different groups exhibit a different patterns of beta weights (whether different models predict success of the different groups).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
1 2 3 4 5 6 7 8 9 | |
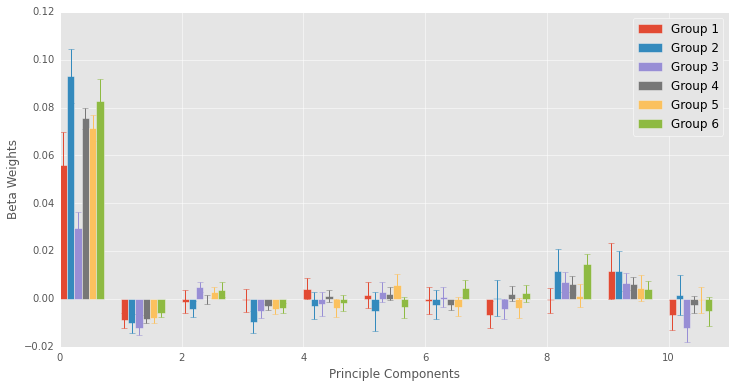
Above I plot the beta weights for each principle component across the groupings. This plot is a lot to look at, but I wanted to depict how the beta values changed across the groups. They are not drastically different, but they’re also not identical. Error bars depict 95% confidence intervals.
Below I fit a regression to each group, but with all the features. Again, multicollinearity will be a problem, but this will not decrease the regression’s accuracy, which is all I really care about.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
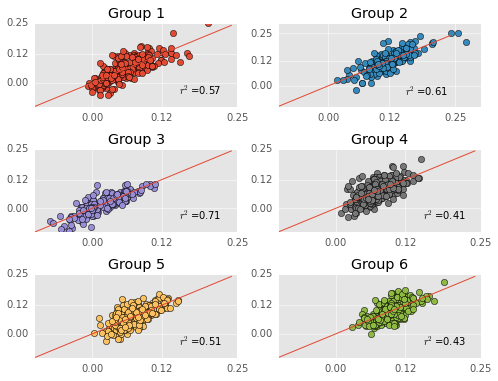
The plots above depict each regression’s predictions against actual ws/48. I provide each model’s r^2 in the plot too.
Some regressions are better than others. For instance, the regression model does a pretty awesome job predicting the bench warmers…I wonder if this is because they have shorter careers… The regression model does not do a good job predicting the 3-point shooters.
Now onto the fun stuff though.
Below, create a function for predicting a players career WS/48. First, I write a function that finds what cluster a player would belong to, and what the regression model predicts for this players career (with 95% confidence intervals).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Here I create a function that creates a list of all the first round draft picks from a given year.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Below I create predictions for each first-round draft pick from 2015. The spurs’ first round pick, Nikola Milutinov, has yet to play so I do not create a prediction for him.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
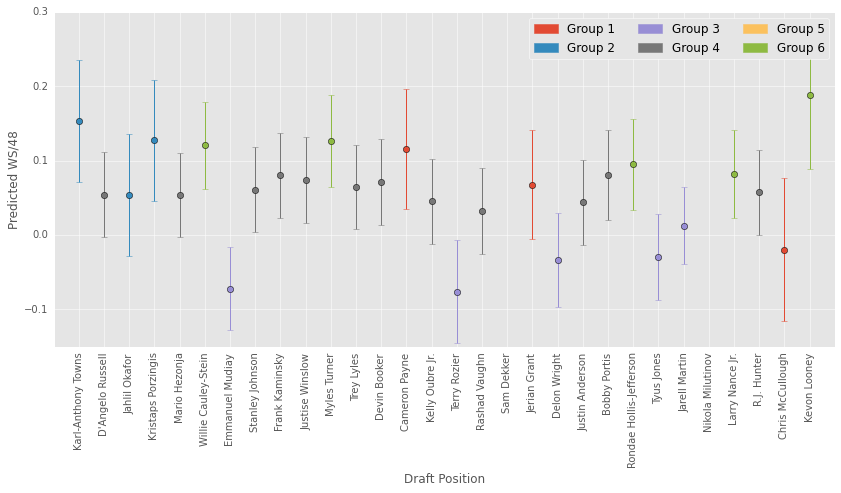
The plot above is ordered by draft pick. The error bars depict 95% confidence interbals…which are a little wider than I would like. It’s interesting to look at what clusters these players fit into. Lots of 3-pt shooters! It could be that rookies play a limited role in the offense - just shooting 3s.
As a t-wolves fan, I am relatively happy about the high prediction for Karl-Anthony Towns. His predicted ws/48 is between Marc Gasol and Elton Brand. Again, the CIs are quite wide, so the model says there’s a 95% chance he is somewhere between Lebron James ever and a player that averages less than 0.1 ws/48.
Karl-Anthony Towns would have the highest predicted ws/48 if it were not for Kevin Looney who the model loves. Kevin Looney has not seen much playing time though, which likely makes his prediction more erratic. Keep in mind I did not use draft position as a predictor in the model.
Sam Dekker has a pretty huge error bar, likely because of his limited playing time this year.
While I fed a ton of features into this model, it’s still just a linear regression. The simplicity of the model might prevent me from making more accurate predictions.
I’ve already started playing with some more complex models. If those work out well, I will post them here. I ended up sticking with a plain linear regression because my vast number of features is a little unwieldy in a more complex models. If you’re interested (and the models produce better results) check back in the future.
For now, these models explain between 40 and 70% of the variance in career ws/48 from only a player’s rookie year. Even predicting 30% of variance is pretty remarkable, so I don’t want to trash on this part of the model. Explaining 65% of the variance is pretty awesome. The model gives us a pretty accurate idea of how these “bench players” will perform. For instance, the future does not look bright for players like Emmanuel Mudiay and Tyus Jones. Not to say these players are doomed. The model assumes that players will retain their grouping for the entire career. Emmanuel Mudiay and Tyus Jones might start performing more like distributors as their career progresses. This could result in a better career.
One nice part about this model is it tells us where the predictions are less confident. For instance, it is nice to know that we’re relatively confident when predicting bench players, but not when we’re predicting 3-point shooters.
For those curious, I output each groups regression summary below.
1
| |
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.648
Model: OLS Adj. R-squared: 0.575
Method: Least Squares F-statistic: 8.939
Date: Sun, 20 Mar 2016 Prob (F-statistic): 2.33e-24
Time: 10:40:28 Log-Likelihood: 493.16
No. Observations: 212 AIC: -912.3
Df Residuals: 175 BIC: -788.1
Df Model: 36
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const -0.1072 0.064 -1.682 0.094 -0.233 0.019
x1 0.0012 0.001 0.925 0.356 -0.001 0.004
x2 -0.0005 0.000 -2.355 0.020 -0.001 -7.53e-05
x3 -0.0005 0.000 -1.899 0.059 -0.001 2.03e-05
x4 3.753e-05 1.27e-05 2.959 0.004 1.25e-05 6.26e-05
x5 -0.1152 0.088 -1.315 0.190 -0.288 0.058
x6 0.0240 0.053 0.456 0.649 -0.080 0.128
x7 -0.4318 0.372 -1.159 0.248 -1.167 0.303
x8 0.0089 0.085 0.105 0.917 -0.159 0.177
x9 -0.0479 0.054 -0.893 0.373 -0.154 0.058
x10 -0.0055 0.021 -0.265 0.792 -0.046 0.035
x11 -0.0011 0.076 -0.015 0.988 -0.152 0.149
x12 -0.0301 0.053 -0.569 0.570 -0.134 0.074
x13 0.7814 0.270 2.895 0.004 0.249 1.314
x14 -0.0323 0.028 -1.159 0.248 -0.087 0.023
x15 -0.0108 0.007 -1.451 0.149 -0.025 0.004
x16 -0.0202 0.030 -0.676 0.500 -0.079 0.039
x17 -0.0461 0.039 -1.172 0.243 -0.124 0.032
x18 -0.0178 0.040 -0.443 0.659 -0.097 0.062
x19 0.0450 0.038 1.178 0.240 -0.030 0.121
x20 0.0354 0.014 2.527 0.012 0.008 0.063
x21 -0.0418 0.044 -0.947 0.345 -0.129 0.045
x22 -0.0224 0.015 -1.448 0.150 -0.053 0.008
x23 -0.0158 0.008 -2.039 0.043 -0.031 -0.001
x24 0.0058 0.001 4.261 0.000 0.003 0.009
x25 0.0577 0.027 2.112 0.036 0.004 0.112
x26 -0.1913 0.267 -0.718 0.474 -0.717 0.335
x27 -0.0050 0.093 -0.054 0.957 -0.189 0.179
x28 -0.0133 0.039 -0.344 0.731 -0.090 0.063
x29 -0.0071 0.015 -0.480 0.632 -0.036 0.022
x30 -0.0190 0.010 -1.973 0.050 -0.038 5.68e-06
x31 0.0221 0.023 0.951 0.343 -0.024 0.068
x32 -0.0083 0.003 -2.490 0.014 -0.015 -0.002
x33 0.0386 0.031 1.259 0.210 -0.022 0.099
x34 0.0153 0.008 1.819 0.071 -0.001 0.032
x35 -1.734e-05 0.001 -0.014 0.989 -0.002 0.002
x36 0.0033 0.004 0.895 0.372 -0.004 0.011
==============================================================================
Omnibus: 2.457 Durbin-Watson: 2.144
Prob(Omnibus): 0.293 Jarque-Bera (JB): 2.475
Skew: 0.007 Prob(JB): 0.290
Kurtosis: 3.529 Cond. No. 1.78e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.78e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.443
Model: OLS Adj. R-squared: 0.340
Method: Least Squares F-statistic: 4.307
Date: Sun, 20 Mar 2016 Prob (F-statistic): 1.67e-11
Time: 10:40:28 Log-Likelihood: 447.99
No. Observations: 232 AIC: -822.0
Df Residuals: 195 BIC: -694.4
Df Model: 36
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const -0.0532 0.090 -0.594 0.553 -0.230 0.124
x1 -0.0020 0.002 -1.186 0.237 -0.005 0.001
x2 -0.0006 0.000 -1.957 0.052 -0.001 4.47e-06
x3 -0.0007 0.000 -2.559 0.011 -0.001 -0.000
x4 5.589e-05 1.39e-05 4.012 0.000 2.84e-05 8.34e-05
x5 0.0386 0.093 0.414 0.679 -0.145 0.222
x6 -0.0721 0.051 -1.407 0.161 -0.173 0.029
x7 -0.6259 0.571 -1.097 0.274 -1.751 0.499
x8 -0.0653 0.079 -0.822 0.412 -0.222 0.091
x9 0.0756 0.051 1.485 0.139 -0.025 0.176
x10 -0.0046 0.031 -0.149 0.881 -0.066 0.057
x11 -0.0365 0.066 -0.554 0.580 -0.166 0.093
x12 0.0679 0.051 1.332 0.185 -0.033 0.169
x13 0.0319 0.183 0.174 0.862 -0.329 0.393
x14 0.0106 0.040 0.262 0.793 -0.069 0.090
x15 -0.0232 0.017 -1.357 0.176 -0.057 0.011
x16 -0.1121 0.039 -2.869 0.005 -0.189 -0.035
x17 -0.0675 0.060 -1.134 0.258 -0.185 0.050
x18 -0.0314 0.059 -0.536 0.593 -0.147 0.084
x19 0.0266 0.055 0.487 0.627 -0.081 0.134
x20 0.0259 0.009 2.827 0.005 0.008 0.044
x21 -0.0155 0.050 -0.307 0.759 -0.115 0.084
x22 0.1170 0.051 2.281 0.024 0.016 0.218
x23 -0.0157 0.014 -1.102 0.272 -0.044 0.012
x24 0.0021 0.003 0.732 0.465 -0.003 0.008
x25 -0.0012 0.038 -0.032 0.974 -0.077 0.075
x26 0.8379 0.524 1.599 0.111 -0.196 1.871
x27 -0.0511 0.113 -0.454 0.651 -0.273 0.171
x28 0.0944 0.111 0.852 0.395 -0.124 0.313
x29 -0.0018 0.029 -0.061 0.951 -0.059 0.055
x30 -0.0167 0.017 -0.969 0.334 -0.051 0.017
x31 0.0377 0.044 0.854 0.394 -0.049 0.125
x32 -0.0052 0.002 -2.281 0.024 -0.010 -0.001
x33 0.0132 0.037 0.360 0.719 -0.059 0.086
x34 -0.0650 0.028 -2.356 0.019 -0.119 -0.011
x35 -0.0012 0.002 -0.668 0.505 -0.005 0.002
x36 0.0087 0.008 1.107 0.270 -0.007 0.024
==============================================================================
Omnibus: 2.161 Durbin-Watson: 2.000
Prob(Omnibus): 0.339 Jarque-Bera (JB): 1.942
Skew: 0.222 Prob(JB): 0.379
Kurtosis: 3.067 Cond. No. 3.94e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.94e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.358
Model: OLS Adj. R-squared: 0.270
Method: Least Squares F-statistic: 4.050
Date: Sun, 20 Mar 2016 Prob (F-statistic): 1.93e-11
Time: 10:40:28 Log-Likelihood: 645.12
No. Observations: 298 AIC: -1216.
Df Residuals: 261 BIC: -1079.
Df Model: 36
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const 0.0306 0.040 0.763 0.446 -0.048 0.110
x1 -0.0013 0.001 -1.278 0.202 -0.003 0.001
x2 -0.0003 0.000 -1.889 0.060 -0.001 1.39e-05
x3 -0.0002 0.000 -1.196 0.233 -0.001 0.000
x4 2.388e-05 8.83e-06 2.705 0.007 6.5e-06 4.13e-05
x5 -0.0643 0.089 -0.724 0.470 -0.239 0.111
x6 0.0131 0.046 0.286 0.775 -0.077 0.103
x7 -0.4703 0.455 -1.034 0.302 -1.366 0.426
x8 0.0194 0.089 0.219 0.827 -0.155 0.194
x9 -0.0330 0.052 -0.638 0.524 -0.135 0.069
x10 -0.0221 0.013 -1.754 0.081 -0.047 0.003
x11 0.0161 0.074 0.216 0.829 -0.130 0.162
x12 -0.0228 0.047 -0.489 0.625 -0.115 0.069
x13 0.2619 0.423 0.620 0.536 -0.570 1.094
x14 -0.0303 0.027 -1.136 0.257 -0.083 0.022
x15 -0.0023 0.003 -0.895 0.372 -0.007 0.003
x16 0.0005 0.023 0.021 0.983 -0.045 0.046
x17 0.0206 0.040 0.513 0.608 -0.059 0.100
x18 0.0507 0.040 1.271 0.205 -0.028 0.129
x19 -0.0349 0.037 -0.942 0.347 -0.108 0.038
x20 0.0210 0.017 1.252 0.212 -0.012 0.054
x21 0.0400 0.041 0.964 0.336 -0.042 0.122
x22 -0.0239 0.009 -2.530 0.012 -0.042 -0.005
x23 -0.0140 0.008 -1.683 0.094 -0.030 0.002
x24 0.0045 0.001 4.594 0.000 0.003 0.006
x25 0.0264 0.026 1.004 0.316 -0.025 0.078
x26 0.2730 0.169 1.615 0.107 -0.060 0.606
x27 -0.0208 0.187 -0.111 0.912 -0.389 0.348
x28 -0.0007 0.015 -0.051 0.959 -0.029 0.028
x29 0.0168 0.018 0.917 0.360 -0.019 0.053
x30 0.0059 0.011 0.524 0.601 -0.016 0.028
x31 -0.0196 0.028 -0.711 0.478 -0.074 0.035
x32 -0.0035 0.004 -0.899 0.370 -0.011 0.004
x33 -0.0246 0.029 -0.858 0.392 -0.081 0.032
x34 0.0145 0.005 2.903 0.004 0.005 0.024
x35 -0.0017 0.001 -1.442 0.150 -0.004 0.001
x36 0.0069 0.005 1.514 0.131 -0.002 0.016
==============================================================================
Omnibus: 5.509 Durbin-Watson: 1.845
Prob(Omnibus): 0.064 Jarque-Bera (JB): 5.309
Skew: 0.272 Prob(JB): 0.0703
Kurtosis: 3.362 Cond. No. 3.70e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.7e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.304
Model: OLS Adj. R-squared: 0.248
Method: Least Squares F-statistic: 5.452
Date: Sun, 20 Mar 2016 Prob (F-statistic): 4.41e-19
Time: 10:40:28 Log-Likelihood: 1030.4
No. Observations: 486 AIC: -1987.
Df Residuals: 449 BIC: -1832.
Df Model: 36
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const 0.1082 0.033 3.280 0.001 0.043 0.173
x1 -0.0018 0.001 -2.317 0.021 -0.003 -0.000
x2 -0.0005 0.000 -3.541 0.000 -0.001 -0.000
x3 4.431e-05 0.000 0.359 0.720 -0.000 0.000
x4 1.71e-05 6.08e-06 2.813 0.005 5.15e-06 2.9e-05
x5 0.0257 0.044 0.580 0.562 -0.061 0.113
x6 0.0133 0.029 0.464 0.643 -0.043 0.070
x7 -0.5271 0.357 -1.476 0.141 -1.229 0.175
x8 0.0415 0.038 1.090 0.277 -0.033 0.116
x9 -0.0117 0.029 -0.409 0.682 -0.068 0.044
x10 0.0031 0.018 0.171 0.865 -0.032 0.038
x11 0.0253 0.031 0.819 0.413 -0.035 0.086
x12 -0.0196 0.028 -0.687 0.492 -0.076 0.036
x13 0.0360 0.067 0.535 0.593 -0.096 0.168
x14 0.0096 0.021 0.461 0.645 -0.031 0.050
x15 0.0101 0.009 1.165 0.245 -0.007 0.027
x16 0.0227 0.015 1.556 0.120 -0.006 0.051
x17 0.0413 0.034 1.198 0.232 -0.026 0.109
x18 0.0195 0.031 0.623 0.533 -0.042 0.081
x19 -0.0267 0.029 -0.906 0.366 -0.085 0.031
x20 0.0199 0.008 2.652 0.008 0.005 0.035
x21 -0.0442 0.033 -1.325 0.186 -0.110 0.021
x22 0.0232 0.025 0.946 0.345 -0.025 0.072
x23 0.0085 0.009 0.976 0.330 -0.009 0.026
x24 0.0025 0.001 1.782 0.075 -0.000 0.005
x25 -0.0200 0.019 -1.042 0.298 -0.058 0.018
x26 0.4937 0.331 1.491 0.137 -0.157 1.144
x27 -0.1406 0.074 -1.907 0.057 -0.286 0.004
x28 -0.0638 0.049 -1.304 0.193 -0.160 0.032
x29 -0.0252 0.015 -1.690 0.092 -0.055 0.004
x30 -0.0217 0.008 -2.668 0.008 -0.038 -0.006
x31 0.0483 0.020 2.387 0.017 0.009 0.088
x32 -0.0036 0.002 -2.159 0.031 -0.007 -0.000
x33 0.0388 0.023 1.681 0.094 -0.007 0.084
x34 -0.0105 0.011 -0.923 0.357 -0.033 0.012
x35 -0.0028 0.001 -1.966 0.050 -0.006 -1.59e-06
x36 -0.0017 0.003 -0.513 0.608 -0.008 0.005
==============================================================================
Omnibus: 5.317 Durbin-Watson: 2.030
Prob(Omnibus): 0.070 Jarque-Bera (JB): 5.115
Skew: 0.226 Prob(JB): 0.0775
Kurtosis: 3.221 Cond. No. 4.51e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 4.51e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.455
Model: OLS Adj. R-squared: 0.378
Method: Least Squares F-statistic: 5.852
Date: Sun, 20 Mar 2016 Prob (F-statistic): 4.77e-18
Time: 10:40:28 Log-Likelihood: 631.81
No. Observations: 289 AIC: -1190.
Df Residuals: 252 BIC: -1054.
Df Model: 36
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const 0.1755 0.096 1.827 0.069 -0.014 0.365
x1 -0.0031 0.001 -2.357 0.019 -0.006 -0.001
x2 -0.0005 0.000 -2.424 0.016 -0.001 -8.68e-05
x3 -0.0003 0.000 -2.154 0.032 -0.001 -2.9e-05
x4 2.374e-05 8.35e-06 2.842 0.005 7.29e-06 4.02e-05
x5 0.0391 0.070 0.556 0.579 -0.099 0.177
x6 0.0672 0.040 1.662 0.098 -0.012 0.147
x7 0.9503 0.458 2.075 0.039 0.048 1.852
x8 -0.0013 0.061 -0.021 0.983 -0.122 0.119
x9 -0.0270 0.041 -0.659 0.510 -0.108 0.054
x10 -0.0072 0.017 -0.426 0.671 -0.041 0.026
x11 0.0604 0.056 1.083 0.280 -0.049 0.170
x12 -0.0723 0.041 -1.782 0.076 -0.152 0.008
x13 -1.2499 0.392 -3.186 0.002 -2.022 -0.477
x14 0.0502 0.028 1.776 0.077 -0.005 0.106
x15 0.0048 0.011 0.456 0.649 -0.016 0.026
x16 -0.0637 0.042 -1.530 0.127 -0.146 0.018
x17 0.0042 0.038 0.112 0.911 -0.070 0.078
x18 0.0318 0.038 0.830 0.408 -0.044 0.107
x19 -0.0220 0.037 -0.602 0.548 -0.094 0.050
x20 -4.535e-05 0.009 -0.005 0.996 -0.018 0.018
x21 -0.0176 0.040 -0.440 0.660 -0.097 0.061
x22 -0.0244 0.021 -1.182 0.238 -0.065 0.016
x23 0.0135 0.012 1.128 0.260 -0.010 0.037
x24 0.0024 0.002 1.355 0.177 -0.001 0.006
x25 -0.0418 0.026 -1.583 0.115 -0.094 0.010
x26 0.3619 0.328 1.105 0.270 -0.283 1.007
x27 0.0090 0.186 0.049 0.961 -0.358 0.376
x28 -0.0613 0.057 -1.068 0.286 -0.174 0.052
x29 0.0124 0.016 0.779 0.436 -0.019 0.044
x30 0.0042 0.011 0.379 0.705 -0.018 0.026
x31 -0.0108 0.026 -0.412 0.681 -0.062 0.041
x32 0.0014 0.002 0.588 0.557 -0.003 0.006
x33 0.0195 0.029 0.672 0.502 -0.038 0.077
x34 0.0168 0.011 1.554 0.121 -0.004 0.038
x35 -0.0026 0.002 -1.227 0.221 -0.007 0.002
x36 -0.0072 0.004 -1.958 0.051 -0.014 4.02e-05
==============================================================================
Omnibus: 4.277 Durbin-Watson: 1.995
Prob(Omnibus): 0.118 Jarque-Bera (JB): 4.056
Skew: 0.226 Prob(JB): 0.132
Kurtosis: 3.364 Cond. No. 4.24e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 4.24e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
OLS Regression Results
==============================================================================
Dep. Variable: WS/48 R-squared: 0.476
Model: OLS Adj. R-squared: 0.337
Method: Least Squares F-statistic: 3.431
Date: Sun, 20 Mar 2016 Prob (F-statistic): 1.19e-07
Time: 10:40:28 Log-Likelihood: 330.36
No. Observations: 173 AIC: -586.7
Df Residuals: 136 BIC: -470.1
Df Model: 36
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const 0.1822 0.262 0.696 0.488 -0.335 0.700
x1 -0.0011 0.002 -0.491 0.624 -0.005 0.003
x2 0.0001 0.000 0.310 0.757 -0.001 0.001
x3 6.743e-05 0.000 0.220 0.827 -0.001 0.001
x4 5.819e-06 1.63e-05 0.357 0.722 -2.65e-05 3.81e-05
x5 0.0618 0.122 0.507 0.613 -0.179 0.303
x6 0.0937 0.074 1.272 0.206 -0.052 0.240
x7 0.8422 0.919 0.917 0.361 -0.975 2.659
x8 -0.1109 0.111 -1.001 0.319 -0.330 0.108
x9 -0.1334 0.075 -1.767 0.079 -0.283 0.016
x10 -0.0357 0.024 -1.500 0.136 -0.083 0.011
x11 -0.1373 0.103 -1.335 0.184 -0.341 0.066
x12 -0.1002 0.075 -1.329 0.186 -0.249 0.049
x13 -0.2963 0.616 -0.481 0.631 -1.515 0.922
x14 -0.0278 0.047 -0.588 0.557 -0.121 0.066
x15 -0.0099 0.015 -0.661 0.510 -0.040 0.020
x16 0.1532 0.106 1.444 0.151 -0.057 0.363
x17 -0.1569 0.072 -2.168 0.032 -0.300 -0.014
x18 -0.1633 0.068 -2.385 0.018 -0.299 -0.028
x19 0.1550 0.066 2.356 0.020 0.025 0.285
x20 -0.0114 0.017 -0.688 0.492 -0.044 0.021
x21 -0.0130 0.076 -0.170 0.865 -0.164 0.138
x22 -0.0202 0.024 -0.857 0.393 -0.067 0.026
x23 -0.0203 0.028 -0.737 0.462 -0.075 0.034
x24 -0.0023 0.004 -0.608 0.544 -0.010 0.005
x25 0.0546 0.048 1.141 0.256 -0.040 0.149
x26 -1.0180 0.714 -1.426 0.156 -2.430 0.394
x27 0.3371 0.203 1.664 0.098 -0.064 0.738
x28 0.1286 0.140 0.916 0.361 -0.149 0.406
x29 -0.0561 0.035 -1.607 0.110 -0.125 0.013
x30 -0.0535 0.020 -2.645 0.009 -0.093 -0.013
x31 0.1169 0.051 2.305 0.023 0.017 0.217
x32 0.0039 0.004 1.030 0.305 -0.004 0.011
x33 0.0179 0.055 0.324 0.746 -0.091 0.127
x34 0.0081 0.013 0.632 0.529 -0.017 0.033
x35 0.0013 0.006 0.229 0.819 -0.010 0.013
x36 -0.0068 0.007 -1.045 0.298 -0.020 0.006
==============================================================================
Omnibus: 2.969 Durbin-Watson: 2.098
Prob(Omnibus): 0.227 Jarque-Bera (JB): 2.526
Skew: 0.236 Prob(JB): 0.283
Kurtosis: 3.357 Cond. No. 6.96e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 6.96e+05. This might indicate that there are
strong multicollinearity or other numerical problems.