We use our most advanced technologies as metaphors for the brain: The industrial revolution inspired descriptions of the brain as mechanical. The telephone inspired descriptions of the brain as a telephone switchboard. The computer inspired descriptions of the brain as a computer. Recently, we have reached a point where our most advanced technologies - such as AI (e.g., Alpha Go), and our current understanding of the brain inform each other in an awesome synergy. Neural networks exemplify this synergy. Neural networks offer a relatively advanced description of the brain and are the software underlying some of our most advanced technology. As our understanding of the brain increases, neural networks become more sophisticated. As our understanding of neural networks increases, our understanding of the brain becomes more sophisticated.
With the recent success of neural networks, I thought it would be useful to write a few posts describing the basics of neural networks.
First, what are neural networks - neural networks are a family of machine learning algorithms that can learn data’s underlying structure. Neural networks are composed of many neurons that perform simple computations. By performing many simple computations, neural networks can answer even the most complicated problems.
Lets get started.
As usual, I will post this code as a jupyter notebook on my github.
1 2 3 4 | |
When talking about neural networks, it’s nice to visualize the network with a figure. For drawing the neural networks, I forked a repository from miloharper and made some changes so that this repository could be imported into python and so that I could label the network. Here is my forked repository.
1 2 3 4 5 6 7 | |
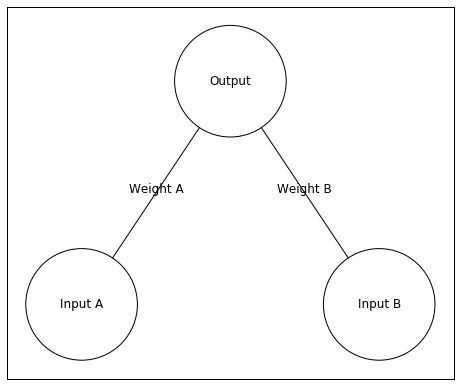
Above is our neural network. It has two input neurons and a single output neuron. In this example, I’ll give the network an input of [0 1]. This means Input A will receive an input value of 0 and Input B will have an input value of 1.
The input is the input unit’s activity. This activity is sent to the Output unit, but the activity changes when traveling to the Output unit. The weights between the input and output units change the activity. A large positive weight between the input and output units causes the input unit to send a large positive (excitatory) signal. A large negative weight between the input and output units causes the input unit to send a large negative (inhibitory) signal. A weight near zero means the input unit does not influence the output unit.
In order to know the Output unit’s activity, we need to know its input. I will refer to the output unit’s input as . Here is how we can calculate
a more general way of writing this is
Let’s pretend the inputs are [0 1] and the Weights are [0.25 0.5]. Here is the input to the output neuron -
Thus, the input to the output neuron is 0.5. A quick way of programming this is through the function numpy.dot which finds the dot product of two vectors (or matrices). This might sound a little scary, but in this case its just multiplying the items by each other and then summing everything up - like we did above.
1 2 3 4 5 | |
0.5
All this is good, but we haven’t actually calculated the output unit’s activity we have only calculated its input. What makes neural networks able to solve complex problems is they include a non-linearity when translating the input into activity. In this case we will translate the input into activity by putting the input through a logistic function.
1 2 | |
Lets take a look at a logistic function.
1 2 3 4 | |
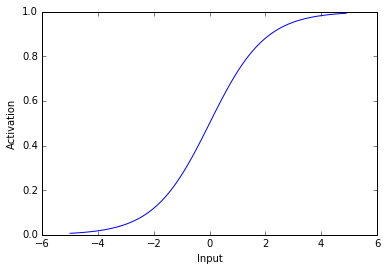
As you can see above, the logistic used here transforms negative values into values near 0 and positive values into values near 1. Thus, when a unit receives a negative input it has activity near zero and when a unit receives a postitive input it has activity near 1. The most important aspect of this activation function is that its non-linear - it’s not a straight line.
Now lets see the activity of our output neuron. Remember, the net input is 0.5
1 2 3 4 5 6 | |
0.622459331202
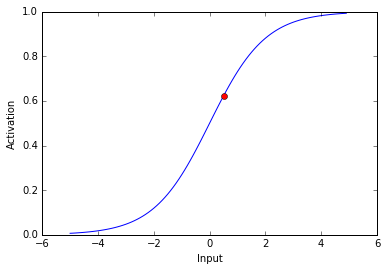
The activity of our output neuron is depicted as the red dot.
So far I’ve described how to find a unit’s activity, but I haven’t described how to find the weights of connections between units. In the example above, I chose the weights to be 0.25 and 0.5, but I can’t arbitrarily decide weights unless I already know the solution to the problem. If I want the network to find a solution for me, I need the network to find the weights itself.
In order to find the weights of connections between neurons, I will use an algorithm called backpropogation. In backpropogation, we have the neural network guess the answer to a problem and adjust the weights so that this guess gets closer and closer to the correct answer. Backpropogation is the method by which we reduce the distance between guesses and the correct answer. After many iterations of guesses by the neural network and weight adjustments through backpropogation, the network can learn an answer to a problem.
Lets say we want our neural network to give an answer of 0 when the left input unit is active and an answer of 1 when the right unit is active. In this case the inputs I will use are [1,0] and [0,1]. The corresponding correct answers will be [0] and [1].
Lets see how close our network is to the correct answer. I am using the weights from above ([0.25, 0.5]).
1 2 3 4 5 6 7 8 9 10 11 | |
[0.56217650088579807, 0.62245933120185459]
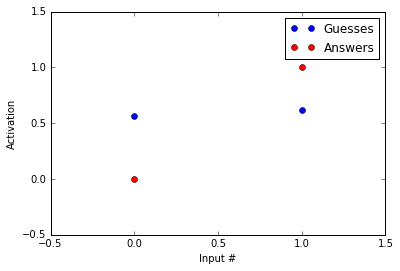
The guesses are in blue and the answers are in red. As you can tell, the guesses and the answers look almost nothing alike. Our network likes to guess around 0.6 while the correct answer is 0 in the first example and 1 in the second.
Lets look at how backpropogation reduces the distance between our guesses and the correct answers.
First, we want to know how the amount of error changes with an adjustment to a given weight. We can write this as
This change in error with changes in the weights has a number of different sub components.
- Changes in error with changes in the output unit’s activity:
- Changes in the output unit’s activity with changes in this unit’s input:
- Changes in the output unit’s input with changes in the weight:
Through the chain rule we know
This might look scary, but with a little thought it should make sense: (starting with the final term and moving left) When we change the weight of a connection to a unit, we change the input to that unit. When we change the input to a unit, we change its activity (written Output above). When we change a units activity, we change the amount of error.
Let’s break this down using our example. During this portion, I am going to gloss over some details about how exactly to derive the partial derivatives. Wikipedia has a more complete derivation.
In the first example, the input is [1,0] and the correct answer is [0]. Our network’s guess in this example was about 0.56.
Please note that this is specific to our example with a logistic activation function
To summarize:
This is the direction we want to move in, but taking large steps in this direction can prevent us from finding the optimal weights. For this reason, we reduce our step size. We will reduce our step size with a parameter called the learning rate (). is bound between 0 and 1.
Here is how we can write our change in weights
This is known as the delta rule.
We will set to be 0.5. Here is how we will calculate the new .
Thus, is shrinking which will move the output towards 0. Below I write the code to implement our backpropogation.
1 2 3 4 5 6 7 | |
Above I use the outer product of our delta function and the input in order to spread the weight changes to all lines connecting to the output unit.
Okay, hopefully you made it through that. I promise thats as bad as it gets. Now that we’ve gotten through the nasty stuff, lets use backpropogation to find an answer to our problem.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
It seems our code has found an answer, so lets see how the amount of error changed as the code progressed.
1 2 3 4 | |
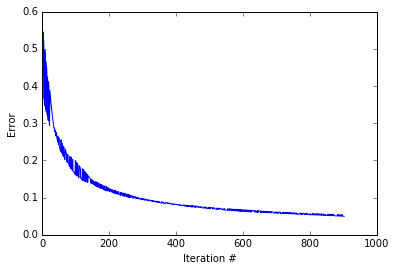
It looks like the while loop excecuted about 1000 iterations before converging. As you can see the error decreases. Quickly at first then slowly as the weights zone in on the correct answer. lets see how our guesses compare to the correct answers.
1 2 3 4 5 6 7 8 9 10 11 | |
[array([ 0.05420561]), array([ 0.95020512])]
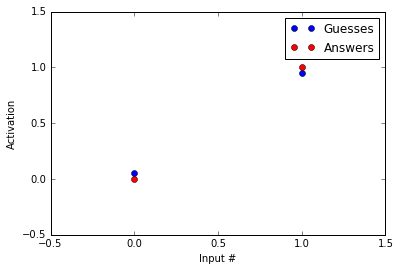
Not bad! Our guesses are much closer to the correct answers than before we started running the backpropogation procedure! Now, you might say, “HEY! But you haven’t reached the correct answers.” That’s true, but note that acheiving the values of 0 and 1 with a logistic function are only possible at - and , respectively. Because of this, we treat 0.05 as 0 and 0.95 as 1.
Okay, all this is great, but that was a really simple problem, and I said that neural networks could solve interesting problems!
Well… this post is already longer than I anticipated. I will follow-up this post with another post explaining how we can expand neural networks to solve more interesting problems.