For some reason I recently got it in my head that I wanted to go back and create more NBA shot charts. My previous shotcharts used colored circles to depict the frequency and effectiveness of shots at different locations. This is an extremely efficient method of representing shooting profiles, but I thought it would be fun to create shot charts that represent a player’s shooting profile continously across the court rather than in discrete hexagons.
By depicting the shooting data continously, I lose the ability to represent one dimenion - I can no longer use the size of circles to depict shot frequency at a location. Nonetheless, I thought it would be fun to create these charts.
I explain how to create them below. I’ve also included the ability to compare a player’s shooting performance to the league average.
In my previous shot charts, I query nba.com’s API when creating a players shot chart, but querying nba.com’s API for every shot taken in 2015-16 takes a little while (for computing league average), so I’ve uploaded this data to my github and call the league data as a file rather than querying nba.com API.
This code is also available as a jupyter notebook on my github.
1 2 3 | |
Here, I create a function for querying shooting data from NBA.com’s API. This is the same function I used in my previous post regarding shot charts.
You can find a player’s ID number by going to the players nba.com page and looking at the page address. There is a python library that you can use for querying player IDs (and other data from the nba.com API), but I’ve found this library to be a little shaky.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Create a function for drawing the nba court. This function was taken directly from Savvas Tjortjoglou’s post on shot charts.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
Write a function for acquiring each player’s picture. This isn’t essential, but it makes things look nicer. This function takes a playerID number and the amount to zoom in on an image as the inputs. It by default places the image at the location 500,500.
1 2 3 4 5 6 7 8 9 | |
Here is where things get a little complicated. Below I write a function that divides the shooting data into a 25x25 matrix. Each shot taken within the xy coordinates encompassed by a given bin counts towards the shot count in that bin. In this way, the method I am using here is very similar to my previous hexbins (circles). So the difference just comes down to I present the data rather than how I preprocess it.
This function takes a dataframe with a vector of shot locations in the X plane, a vector with shot locations in the Y plane, a vector with shot type (2 pointer or 3 pointer), and a vector with ones for made shots and zeros for missed shots. The function by default bins the data into a 25x25 matrix, but the number of bins is editable. The 25x25 bins are then expanded to encompass a 500x500 space.
The output is a dictionary containing matrices for shots made, attempted, and points scored in each bin location. The dictionary also has the player’s ID number.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
Below I load the league average data. I also have the code that I used to originally download the data and to preprocess it.
1 2 3 4 5 6 7 8 9 | |
I really like playing with the different color maps, so here is a new color map I created for these shot charts.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Below, I write a function for creating the nba shot charts. The function takes a dictionary with martrices for shots attempted, made, and points scored. The matrices should be 500x500. By default, the shot chart depicts the number of shots taken across locations, but it can also depict the number of shots made, field goal percentage, and point scored across locations.
The function uses a gaussian kernel with standard deviation of 5 to smooth the data (make it look pretty). Again, this is editable. By default the function plots a players raw data, but it will plot how a player compares to league average if the input includes a matrix of league average data.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | |
Alright, thats that. Now lets create some plots. I am a t-wolves fan, so I will plot data from Karl Anthony Towns.
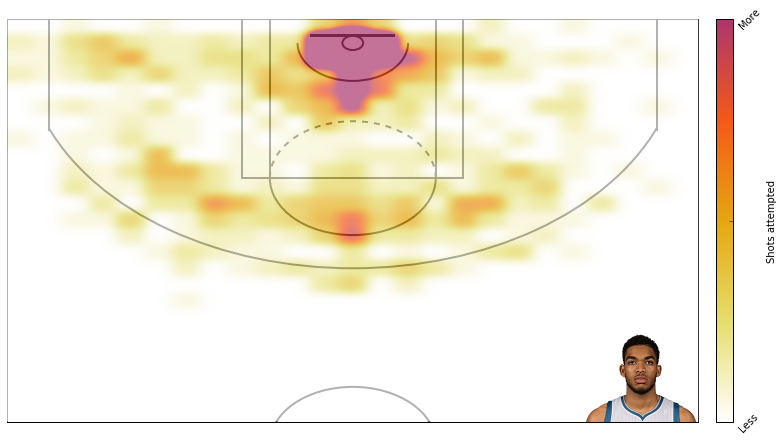
First, here is the default plot - attempts.
1 2 3 | |
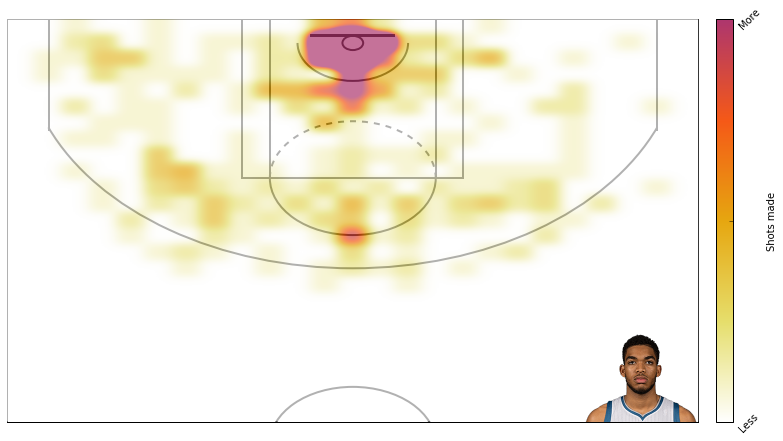
Here’s KAT’s shots made
1 2 3 | |
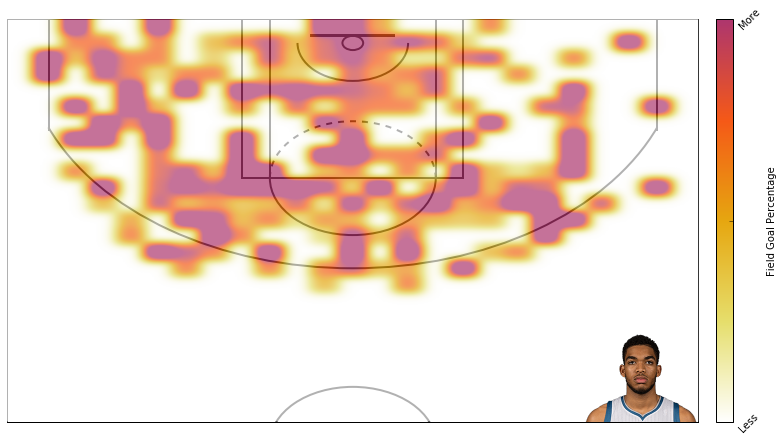
Here’s field goal percentage. I don’t like this one too much. It’s hard to use similar scales for attempts and field goal percentage even though I’m using standard deviations rather than absolute scales.
1 2 3 | |
Here’s points across the court.
1 2 3 | |
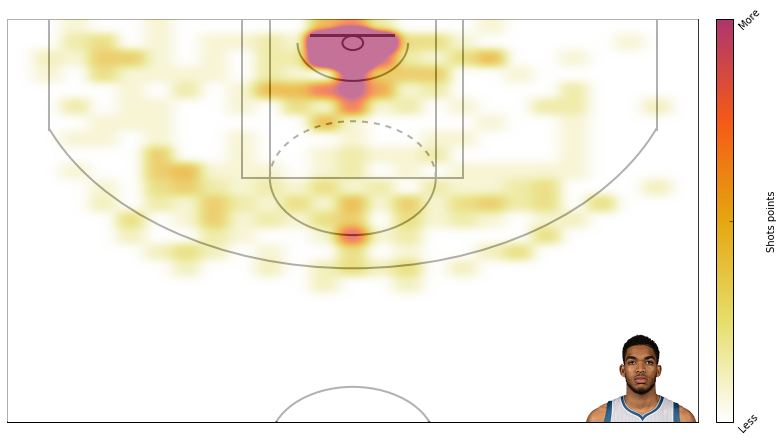
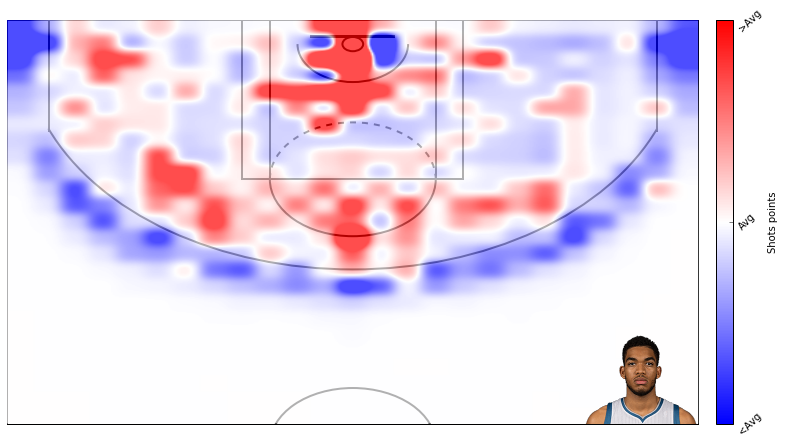
Here’s how KAT’s attempts compare to the league average. You can see the twolve’s midrange heavy offense.
1 2 3 | |
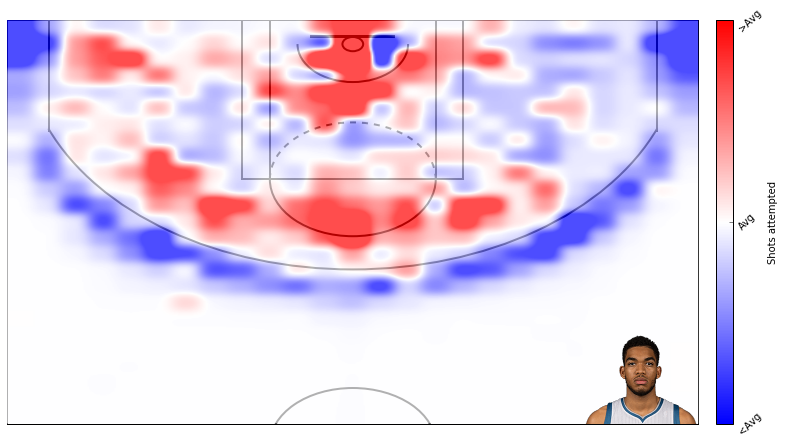
How KAT’s shots made compares to league average.
1 2 3 | |
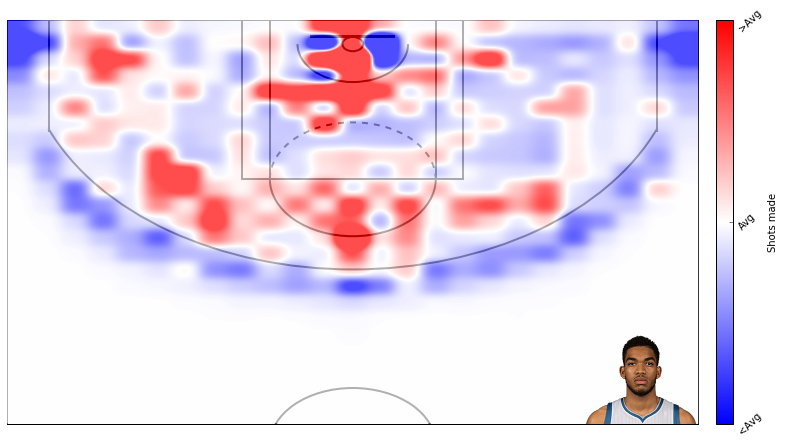
How KAT’s field goal percentage compares to league average. Again, the scale on these is not too good.
1 2 3 | |
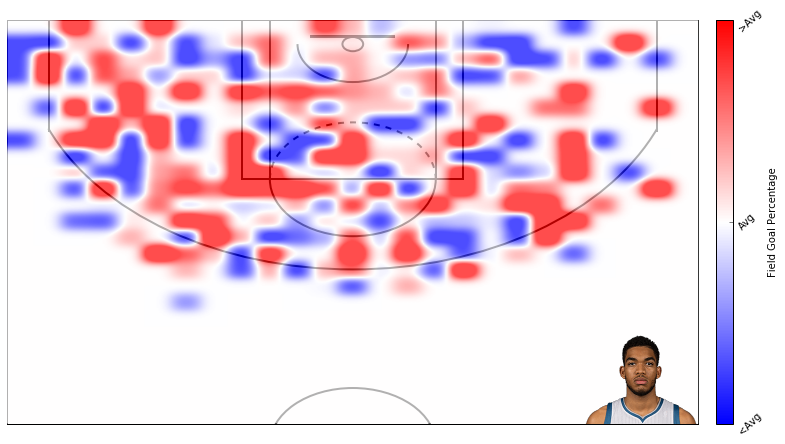
And here is how KAT’s points compare to league average.
1 2 3 | |