This summer I had the pleasure of attending the Brains, Minds, and Machines summer course at the Marine Biology Laboratory. While there, I saw cool research, met awesome scientists, and completed an independent project. In this blog post, I describe my project.
In 2012, Krizhevsky et al. released a convolutional neural network that completely blew away the field at the imagenet challenge. This model is called “Alexnet,” and 2012 marks the beginning of neural networks’ resurgence in the machine learning community.
Alexnet’s domination was not only exciting for the machine learning community. It was also exciting for the visual neuroscience community whose descriptions of the visual system closely matched alexnet (e.g., HMAX). Jim DiCarlo gave an awesome talk at the summer course describing his research comparing the output of neurons in the visual system and the output of “neurons” in alexnet (you can find the article here).
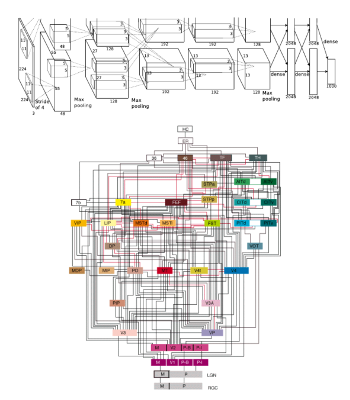
I find the similarities between the visual system and convolutional neural networks exciting, but check out the depictions of alexnet and the visual system above. Alexnet is depicted in the upper image. The visual system is depicted in the lower image. Comparing the two images is not fair, but the visual system is obviously vastly more complex than alexnet.
In my project, I applied a known complexity of the biological visual system to a convolutional neural network. Specifically, I incoporated visual attention into the network. Visual attention refers to our ability to focus cognitive processing onto a subset of the environment. Check out this video for an incredibly 90s demonstration of visual attention.
In this post, I demonstrate that implementing a basic version of visual attention in a convolutional neural net improves performance of the CNN, but only when classifying noisy images, and not when classifying relatively noiseless images.
Code for everything described in this post can be found on my github page. In creating this model, I cribbed code from both Jacob Gildenblat and this implementation of alexnet.
I implemented my model using the Keras library with a Theano backend, and I tested my model on the MNIST database. The MNIST database is composed of images of handwritten numbers. The task is to design a model that can accurately guess what number is written in the image. This is a relatively easy task, and the best models are over 99% accurate.
I chose MNIST because its an easy problem, which allows me to use a small network. A small network is both easy to train and easy to understand, which is good for an exploratory project like this one.
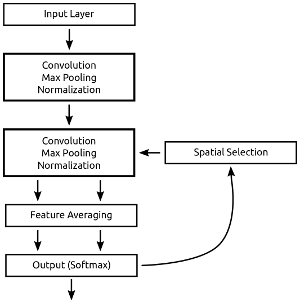
Above, I depict my model. This model has two convolutional layers. Following the convolutional layers is a feature averaging layer which borrows methods from a recent paper out of the Torralba lab and computes the average activity of units covering each location. The output of this feature averaging layer is then passed along to a fully connected layer. The fully connected layer “guesses” what the most likely digit is. My goal when I first created this network was to use this “guess” to guide where the model focused processing (i.e., attention), but I found guided models are irratic during training.
Instead, my current model directs attention to all locations that are predictive of all digits. I haven’t toyed too much with inbetween models - models that direct attention to locations that are predictive of the N most likely digits.
So what does it mean to “direct attention” in this model. Here, directing attention means that neurons covering “attended” locations are more active than neurons covering the unattended locations. I apply attention to the input of the second convolutional layer. The attentionally weighted signal passes through the second convolutional layer and passes onto the feature averaging layer. The feature averaging layer feeds to the fully connected layer, which then produces a final guess about what digit is present.
I first tested this model on the plain MNIST set. For testing, I wanted to compare my model to a model without attention. My comparison model is the same as the model with attention except that the attention directing signal is a matrix of ones - meaning that it doesn’t have any effect on the model’s activity. I use this comparison model because it has the same architecture as the model with attention.
I depict the results of my attentional and comparison models below. On the X-axis is the test phase (10k trials) following each training epoch (60k trials). On the Y-axis is percent accuracy during the test phase. I did 3 training runs with both sets of models. All models gave fairly similar results, which led to small error bars (these depict standard error). The results are … dissapointing. As you can see both the model with attention and the comparison model perform similarly. There might be an initial impact of attention, but this impact is slight.
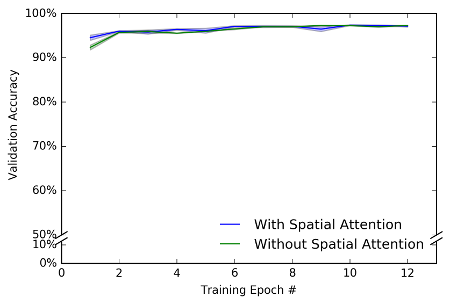
This result was a little dissapointing (since I’m an attention researcher and consider attention an important part of cognition), but it might not be so surprising given the task. If I gave you the task of naming digits, this task would be virtually effortless; probably so effortless that you would not have to pay very much attention to the task. You could probably talk on the phone or text while doing this task. Basically, I might have failed to find an effect of attention because this task is so easy that it does not require attention.
I decided to try my network when the task was a little more difficult. To make the task more difficult, I added random noise to each image (thank you to Nancy Kanwisher for the suggestion). This trick of adding noise to images is one that’s frequently done in psychophysical attention expeirments, so it would be fitting if it worked here.
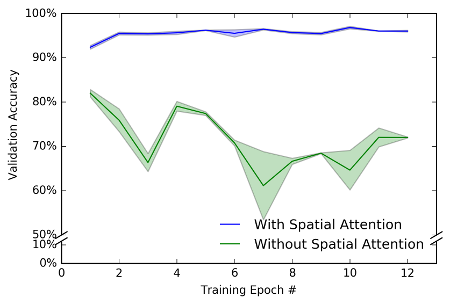
The figure above depicts model performance on noisy images. The models are the as before, but this time the model with attention is far superior to the comparison model. Good news for attention researchers! This work suggests that visual attentional mechanisms similar to those in the brain may be beneficial in convolutional neural networks, and this effect is particularly strong with the images are noisy.
This work bears superficial similarity to recent language translation and question answering models. Models like the cited one report using a biologically inspired version of attention, and I agree they do, but they do not use attention in the same way that I am here. I believe this difference demonstrates a problem with what we call “attention.” Attention is not a single cognitive process. Instead, its a family of cognitive processes that we’ve simply given the same name. Thats not to say these forms of attention are completely distinct, but they likely involve different information transformations and probably even different brain regions.